







Машинное обучение против мошенничества в банковской сфере

При разработке новых цифровых сервисов Сбербанк ставит безопасность транзакций и средств своих клиентов во главу угла. В банке работает эшелонированная защита всех онлайн-услуг. Она включает ряд защитных механизмов: подтверждение операций с помощью одноразовых паролей, шифрование трафика, использование встроенных антивирусных решений в приложениях и т. д.
Одним из элементов такой защиты выступает система выявления и предотвращения мошеннических транзакций. О том, что собой представляет такая система и какие вызовы возникают при ее реализации, мы и поговорим.
Исторический подход
На заре появления кибермошенничества в России в Сбербанке для выявления мошеннических транзакций использовался набор правил. Его создавали эксперты банка, регулярно анализирующие и работающие с кейсами мошенничества. Обычно каждое из правил представляло собой совокупность жестких условий, при выполнении которых транзакция считалась подозрительной:
ЕСЛИ (интернет-провайдер, новый для клиента) И (сумма транзакции > 20 000) И (получатель платежа, новый для клиента) ? доп. проверка.
Жесткие условия, при несоблюдении которых правила не срабатывали, были их существенным недостатком.
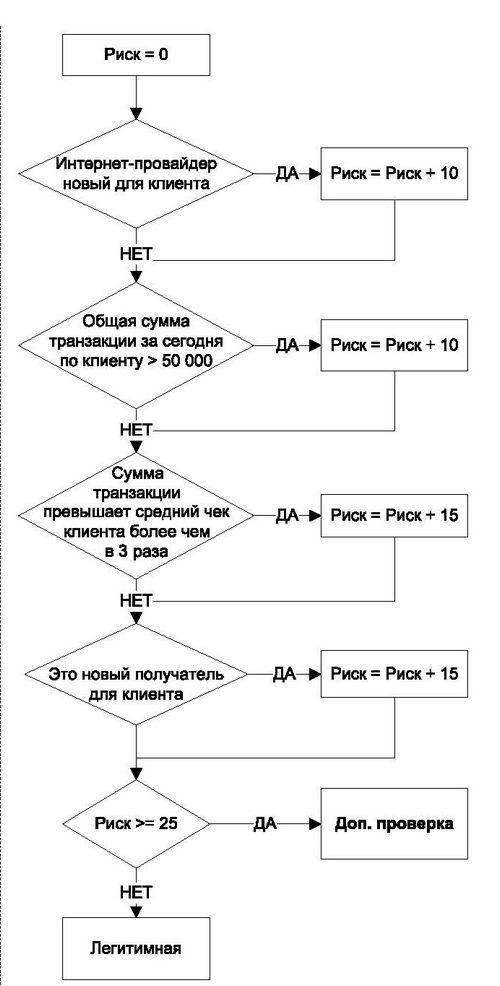
Следующим этапом развития системы выявления мошенничества в Сбербанке было построение алгоритмов-правил с большим количеством гибких условий и использованием клиентозависимых величин. В таких правилах выполнение каждого из условий увеличивает оценку риска на некоторую величину, и если итоговая оценка превышает порог, транзакция считается подозрительной и отправляется на дополнительную проверку.
В вымышленном примере, изображенном на рисунке, наличие двух любых условий приведет к тому, что оценка риска станет равна 25 и транзакция будет отправлена на дополнительную проверку.
Правила, построенные по такому принципу, не только усложняют их обход, но и позволяют снизить число ложных срабатываний, так как учитывают индивидуальные особенности и характер транзакций клиентов.
Однако ключевой недостаток систем, построенных на наборах правил, оставался и в этом случае. Эксперты должны были постоянно актуализировать и донастраивать такие системы вручную, потому что мошенники подстраиваются под защитные механизмы и ищут пути их обхода. К другим недостаткам систем выявления мошенничества, построенных на основе правил, можно отнести: ·
-
небольшое число используемых параметров (редко аналитики используют в правилах более 10 бизнес-параметров в одном правиле и, как следствие, выявляют только очевидные корреляции между параметрами и фродом);
-
они субъективны (у каждого эксперта из приведенного примера может быть своя оценка веса риска условий, и это не дает вероятностные оценки — такая особенность не позволяет ранжировать сработки);
-
позволяют обнаруживать только уже известные кейсы фрода;
-
число правил постоянно растет, и процесс их поддержки в актуальном состоянии — отдельная сложная задача.
Data Driven
Растущие объемы транзакций в удаленных каналах обслуживания, появление новых платежных инструментов, усложнение мошеннических схем — эти факторы сыграли решающую роль при реализации Сбербанком системы выявления мошенничества (далее по тексту — СВМ). Во-первых, она должна была быть масштабируемой, во-вторых, проактивной и, наконец, в ней не должно было быть описанных выше недостатков. Для решения данной задачи специалисты по кибербезопасности Сбербанка при создании СВМ использовали методы машинного обучения.
Можно сказать, что машинное обучение является ничем иным, как Data Driven-подходом к решению задачи, то есть на основании данных компьютер сам определяет мошеннические паттерны и строит модель для их выявления.
Этот подход имеет следующие преимущества по сравнению с системой экспертных правил:
-
может выявлять сложные паттерны фрода, используя все доступные параметры и данные;
-
адаптироваться к изменяющимся и появляющимся схемам мошенничества без необходимости постоянно дописывать новые правила;
-
результатом работы является вероятность мошенничества — число, которое можно ранжировать;
-
обрабатывать и обучаться на очень больших объемах данных;
-
выявлять ранее не известные типы фрода (аномалии в транзакциях).
Однако этот подход не лишен и недостатков:
-
для обучения таких систем зачастую требуется большое количество прецедентов (примеров)
-
многие модели представляют собой «черные ящики», не позволяющие определить, почему та или иная транзакция была определена как подозрительная
В качестве примера рассмотрим задачу выявления мошеннических транзакций по картам, но описанные подходы актуальны и для других каналов, например интернет-банка. Процесс проведения транзакции можно представить в виде следующих шагов:
-
автоматизированная система при проведении операции отправляет ее на оценку в СВМ;
-
СВМ, используя доступные данные по транзакции и дополнительные источники, проводит оценку риска транзакции;
-
если оценка риска ниже установленного порога, то операция отправляется на исполнение;
-
если оценка риска выше установленного порога, то операция отправляется на дополнительную проверку валидаторам;
-
валидаторы по результатам проверки (например, обратной связи от клиента) либо разрешают, либо отклоняют операцию;
-
результат проверки события фиксируется и возвращается в качестве обратной связи в СВМ;
-
дополнительно фиксируется информация о мошенничестве, которая поступает от клиентов и не была выявлена системой. Эти данные также используются для обучения.
Главным компонентом СВМ является модель, реализующая скоринг транзакций. Отметим, что для решения данной задачи мы будем рассматривать наиболее распространенный supervised-подход (обучение с учителем).
Недостаточность данных из транзакции
Один из первых вопросов, возникающих при решении задачи создания модели выявления мошенничества, — как создать выборки для обучения и оценки нашей модели.
Разделение транзакций на мошеннические и легитимные происходит в результате дополнительных проверок сработок текущей системы выявления случаев мошенничества или обращений по проблемам с мошенничеством от клиентов. Однако с пространством признаков, описывающих события, не все так однозначно.
В СВМ приходят следующие сведения о транзакциях: номер карты/идентификатор клиента, сумма, дата, время, тип операции, наименование поставщика услуг, способ подтверждения и несколько других. Информации о поведении клиента в них не содержится.
Практика службы кибербезопасности Сбербанка показывает, что для построения эффективной СВМ в дополнение к имеющимся данным о транзакциях следует создать дополнительные признаки, описывающие поведение клиента.
При создании признаков используется широкий набор различного рода агрегаций, математических функций: перцентили, средние и отклонения, скользящие окна и многое другое. Примеры возможных признаков:
-
среднее расходов клиента в разрезе типов операций со скользящим недельным окном за последние три месяца, его среднеквадратичное отклонение;
-
среднее/перцентили расходов клиента в разрезе типов операций с дневным скользящим окном за последний месяц;
-
число предыдущих транзакций по данному мерчанту всего/за последние 30 дней;
-
время текущей транзакции относительно распределения времени проведения операций клиентом за последние три месяца;
-
наличие жалоб на поставщика услуг за последний месяц и т. д.
Помимо признаков, основанных только на количественных/частотных показателях предыдущих транзакций клиента, специалисты Службы кибербезопасности Сбербанка используют также графовые представления операций. Таким образом можно получить дополнительные признаки, релевантные для выявления мошеннических операций.
На данный момент у нас есть свыше 50 различных базовых критериев, которые при комбинациях и объединениях дают больше 200 итоговых признаков, использующихся в моделях.
Метрики оценки эффективности
Прежде чем перейти к обучению модели, нужно понять, как оценивать ее качество. Без этого невозможно сравнивать разные решения и фиксировать улучшения. Выбор метрик для оценки эффективности модели — нетривиальная задача по ряду причин:
1) сильная несбалансированность классов;
2) сложность определения стоимости правильной и неправильной классификации фрода;
3) ограничение на число обрабатываемых событий (выделенные ресурсы на разбор), генерируемых СВМ.
Традиционные метрики, такие как точность (accuracy) или уровень ошибки (error rate), не подходят из-за сильной несбалансированности классов. Например, при доле фрода 0,1 %, предсказывая все транзакции как легитимные, мы получаем точность 99,9 %.
Более релевантными метриками в подобных задачах являются F-мера (гармоническое среднее) и G-мера (геометрическое среднее). Обе величины при своем расчете учитывают и точность, и полноту модели. В частности, F-мера в описанном случае (предсказывать все транзакции как легитимные) равна 0. F-мера идеального классификатора равна 1. Однако обе они зависят от выбранного порога срабатывания классификатора, вот почему важно оценивать эти величины на различных порогах.
Другая метрика, часто используемая в задачах с несбалансированными классами, — AUC, оценивающая интегральный показатель качества модели независимо от выбора порога
Вместе с тем AUC выражает эффективность классификатора на всем множестве, тогда как нас зачастую интересует эффективность только до определенной зоны порогов отсечек. В таком случае следует воспользоваться partialAUC.
Представленные метрики характеризуют качество классификации модели. Но для задачи выявления мошенничества пригодны и метрики из области ранжирования — фродовые кейсы ранжируют максимально высоко, что особенно важно в условиях ограниченного объема обрабатываемых валидаторами событий.
Лучше всего подходят такие метрики, как Average Precision (AP) и Average Pricison at K (AP@k). AP аналогично AUC оценивает модель на всем множестве значений, тогда как AP@k определяет качество ранжирования на топ-k-элементах. Обе метрики тем больше, чем выше модель ранжирует кейсы мошенничества относительно легитимных транзакций. Модель, которая все фродовые события классифицирует выше легитимных, будет иметь показатели, равные 1.
Выбор метрик в каждом конкретном случае зависит от поставленной задачи, ограничений и доступности данных.
Проблему выявления мошеннических транзакций по картам мы в своей практике решаем с помощью метрик AP@k, precision/recall и partialAUC в пределах порога модели, соответствующего допустимому объему срабатываний.
Методы out-of-box не работают
Объемы карточных транзакций составляют сотни миллионов штук. А доля мошенничества в них не превышает сотых или даже тысячных долей процента — это очень сильная несбалансированность классов транзакций, так называемая unbalanced problem. Кроме того, их распределение сильно пересекается (class overlaping) — мошенники стараются проводить транзакции таким образом, чтобы они максимально походили на легитимные.
В результате большинство алгоритмов, обученных на подобных несбалансированных данных, демонстрируют плохие результаты, поскольку оптимизируют такие величины, как уровень ошибки (error rate) без учета распределений между классами. В худшем случае получается тривиальный классификатор, который всегда определяет транзакцию как легитимную.
В решении данной проблемы (unbalance + overlapping) можно выделить две группы: методы, работающие на уровне данных (data level) и на уровне алгоритмов (algorithm level).
При использовании первой группы методов данные преобразуются на этапе препроцессинга (до начала обучения алгоритма) так, чтобы в результате получить более сбалансированный и очищенный набор сведений. Методы на уровне данных можно разделить на следующие группы:
-
сэмплирование (under- и oversampling), в результате которого происходит или прореживание основного класса, или же дублирование/искусственная генерация (SMOTE) примеров минорного класса;
-
методы, основанные на вычислении расстояний (distance-based), в которых обычно происходит прореживание основного класса, но с учетом расстояний до границ классов и/или удаление шумовых/граничных примеров каждого из классов. Примеры таких алгоритмов — Tomek link, One Sided Selection, Neighborhood Cleaning Rule.
Методы на уровне алгоритмов заключаются в модификации существующих и разработке новых алгоритмов с учетом неравномерного распределения транзакций и минорного класса. Примеры таких алгоритмов — HDDT, Box Drawnings. В ряде алгоритмов присутствуют и параметры, позволяющие изменять стоимость ошибки классификации разных классов (cost-sensitive learning). Увеличивая стоимость ошибки минорного класса, мы тем самым повышаем приоритет правильной классификации алгоритмов именно мошеннических транзакций по сравнению с легитимными.
В Сбербанке мы используем подход, который хорошо зарекомендовал себя во многих практических задачах, — комбинацию undersampling-метода и обучения ансамбля классификаторов. Например, BalanceCascade, в котором последовательно обучается серия классификаторов (random forest). При этом на каждом этапе сначала посредством undersampling формируется более сбалансированная выборка и обучается классификатор, а затем из исходного набора данных удаляются корректно классифицированные сэмплы основного класс,а и операция повторяется вновь. Итоговая модель представляет собой набор таких классификаторов.
Еще один часто используемый нами метод — EasyEnsemble. Заметим, что оптимальный уровень сэмплирования (отношение минорного класса к основному) не обязательно должен быть один к одному. Он зависит от данных, а также используемого алгоритма. У нас в некоторых задачах оптимальный параметр получался по-прежнему несбалансированным, но уже не столь экстремальным — один к десяти. Поэтому уровень сэмплирования нужно рассматривать как один из параметров модели и наряду с другими параметрами постоянно его оптимизировать (поиск оптимального значения).
При использовании сэмплирования следует иметь в виду, что оно искривляет апостериорную вероятность, возвращаемую моделью. Это происходит потому, что при подготовке обучающих выборок изменяется соотношение классов по сравнению с реальным распределением в данных. Соответственно, если эту вероятность планируется использовать помимо ранжирования кейсов (например, при блендинге/стэкинге нескольких моделей), то прежде необходимо провести ее калибрацию.
Заключение
К настоящему времени в Сбербанке разработан и внедрен целый ряд моделей для противодействия различным аспектам кибермошенничества (выявления мошеннических транзакций в разных каналах, мошеннических групп и их связей и др.), а также ансамбли из этих моделей.
Переход от статических правил к моделям, построенным с помощью машинного обучения, оказал колоссальное положительное влияние:
-
уровень фрода удалось сократить в несколько раз при постоянном росте транзакционной активности и появлении новых продуктов и услуг;
-
автоматизирован процесс реагирования на модификации и появления новых схем мошенничества, увеличена скорость реакции;
-
улучшен клиентский опыт за счет снижения ложных срабатываний системы, а также повышены лимиты проведения операций;
-
процессы оценки эффективности работы стали прозрачнее.
Кибербезопасность Сбербанка и дальше будет развиваться в направлении применения передовых исследований и разработок в области BigData, Machine Learning, Artificial Intelligence для обеспечения безопасности наших клиентов и банка в целом. Применение таких технологий для противодействия мошенничеству уже не конкурентное преимущество, а жизненная необходимость для адекватного ответа на современные вызовы киберпреступности.
Опубликовано 19.05.2017