







Машинное обучение и информационная безопасность

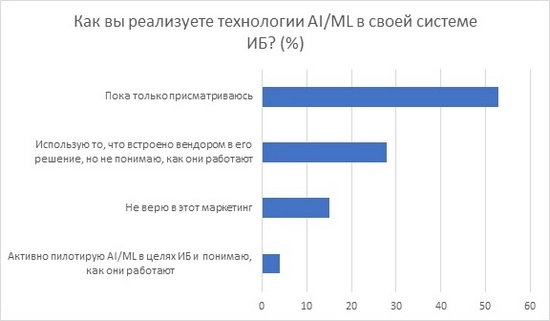
На IDC Security Roadshow 2018 мне довелось провести опрос среди специалистов по кибербезопасности и спросить их о том, обращаются ли они в своей деятельности к искусственному интеллекту или, если быть более конкретным, к машинному обучению. Интересно, что примерно схожее распределение, по данным Gartner, существует и в отношении иных сфер применения искусственного интеллекта (ИИ), что показывает определенное недоверие к этой технологии или непонимание даруемых ею преимуществ. В статье мне хотелось бы посмотреть на то, как может использоваться ИИ и машинное обучение в кибербезопасности.
Традиционная кибербезопасность
К сожалению, надо признать, что сегодня безопасность в массе своей реактивна. Мы боремся с тем, что уже кого-то задело, заразило, вывело из строя, украло деньги. И эффективность системы защиты зависит от того, насколько быстро мы будем узнавать об атаках, с которыми кто-то уже столкнулся.
Вы знаете адрес домена «kill switch», который проверялся нашумевшей вредоносной программой WannaCry и в случае его отсутствия заражал компьютер? Это iuqerfsodp9ifjaposdfjhgosurijfaewrwergwea[.]com, и информацию вы получили от компаний, которые смогли исследовать данную атаку и своевременно предоставить вам соответствующую информацию. А когда стало известно о вредоносной программе Olympic Destroyer, атаковавшей инфраструктуру зимних Олимпийских игр в Южной Корее, то бороться с ней вам позволило знание соответствующего хэша (сигнатуры) db1ff2521fb4bf748111f92786d260d40407a2e8463dcd24bb09f908ee13eb9. А теперь усложним пример. Существует такой вирус-шифровальщик Locky, который заражал в день около 90 тысяч жертв, требуя с них выкуп за возврат доступа к файлам в размере 0,5-1 биткойна. Один из доменов, откуда распространялся Locky, был *.7asel7[.]top. Если мы внесем его в черные списки, то можно ли быть уверенным, что мы защитились от этой угрозы? Увы. Указанный домен был ассоциирован с IP-адресом 185.101.218.206, на котором, в свою очередь, «висело» еще около 1000 вредоносных доменов, например, ccerberhhyed5frqa[.]8211fr[.]top и другие. Самое неприятное, что такие домены могут создаваться тысячами и использоваться не более одного-двух раз. Как защититься от них? Вносить в черный список? Они будут распухать с неимоверной скоростью. Кстати, та же проблема и у антивирусов или систем обнаружения атак, использующих в основе сигнатурные методы обнаружения. У современных антивирусов огромные базы сигнатур, насчитывающие миллиарды записей. При этом ежедневно обнаруживается более миллиона вредоносных программ, и во многих атаках используются уникальные вредоносные программы, с которыми ранее никто не сталкивался.
Что такое машинное обучение
В отличие от традиционных методов обнаружения чего-то плохого, опирающихся на борьбу с чем-то знакомым, машинное обучение позволяет нам распознать то, что еще неизвестно. Чтобы сделать это, на вход модели/алгоритма необходимо подать входные данные (много данных), на которых модель будет обучаться. После обучения модели можно подавать на вход новые данные, и она начнет обнаруживать в них искомое.
Машинное обучение базируется на трех ключевых элементах:
-
Датасет. Чтобы научить модель распознавать что-то (плохое или хорошее), ей на вход надо подать большие объемы данных, называемых датасетом. Это может быть интернет-трафик, сетевые потоки, логи, почтовые сообщения, активность пользователя и многое другое. Чем больше и разнообразнее обучающие данные, тем точнее будет результат предсказания. Чтобы научиться определять спам, нам нужны сотни тысяч и миллионы электронных сообщений для анализа. Чтобы научиться предсказывать поведение пользователя, нужно отслеживать все его действия в течение нескольких недель. Чтобы обнаруживать вредоносные домены, надо изучать сотни миллиардов и триллионы DNS-запросов. От качества датасета зависит эффективность машинного обучения – если данных мало, они неполны или некачественны (а то и вовсе в них могут быть специально внесены некорректные данные), то никакая, даже самая лучшая модель машинного обучения помочь будет не в состоянии.
-
Признаки. Это то, что мы ищем в датасетах. Например, доменное имя, отправитель e-mail, IP-адреc, длительность сетевой сессии, используемый протокол, время дня и т. д. В зависимости от решаемой задачи могут быть сотни различных признаков. Например, у некоторых систем защиты оконечных устройств может быть свыше 400 признаков – это метаданные, ассоциированные с анализируемым файлом: имя, дата создания, размер, наличие сетевых подключений, нестандартные протоколы, использование определенных вызовов, внесение изменений в файловую систему, разработка под определенную архитектуру, обращения к реестру и т. д.
-
Алгоритмы/модели. Найти по определенным признакам искомое в датасете можно различными способами, выбор которых зависит от множества параметров. Правильный выбор алгоритма или модели – это всегда баланс между скоростью работы, аккуратностью предсказания и сложностью модели. А потому обычно на практике экспериментируют с моделями, выбирая из них наиболее подходящую для конкретной задачи.
Виды машинного обучения
Не существует универсального алгоритма машинного обучения (хотя говорят, что нейросеть может претендовать на это звание, но даже типов нейросетей существует два десятка) – разные модели применяются для разных задач. Их принято классифицировать либо по типу обучения, либо по функции, например:
по типу обучения:
-
с учителем,
-
без учителя,
-
с подкреплением;
по функции:
-
регрессия,
-
деревья решений,
-
байесовские,
-
кластеризация,
-
нейросети.
Алгоритмы классического машинного обучения (с учителем или без него) используются в тех случаях, когда у вас простые данные и понятные признаки. К примеру, блокирование платежной карты после снятия наличных за границей. Тут все просто. Обычно все ваши транзакции проходят в домашнем регионе, а тут аномалия – внезапное (если вы не предупредили заранее свой банк о поездке) снятие наличных за пределами страны. Наверное, до 50% всех алгоритмов машинного обучения, используемые в том числе и в ИБ, – нестареющая классика. С ее помощью можно быстро решить нужную задачу.
До 75% всех классических алгоритмов – обучение с учителем, то есть работа с уже размеченными или маркированными данными. Например, модели надо сказать: это спам, а это нет; это DDoS, а это нет; это мошенничество (фрод), а это нет. С помощью обучения с учителем вы сможете легко классифицировать новые данные, выявляя в них нечто аномальное. Посредством таких алгоритмов можно обнаруживать загрузку ранее неизвестного вредоносного кода, спам- и фишинговые атаки, DGA-домены (автоматически создаваемые вредоносные домены), коммуникации с командными серверами и ботнетами. Самыми популярными алгоритмами с учителем можно назвать классификацию и регрессию. Классификация позволяет предсказать категорию, а регрессия – предсказать значение. И если вам нужно предсказать, когда у вас будет рост атак, то вам нужна регрессия, а если вы хотите понять, каких атак у вас будет больше через полгода, понадобится классификация. Каждый из обоих типов может подразделяться на подмножества алгоритмов машинного обучения с учителем. Скажем, к классификации относятся деревья решений, random forest или SVM. С их помощью можно детектировать, в частности, атаки SQL Injection или подозрительный HTTP-трафик.
Но что делать, когда входные данные не размечены? Представим себе, что наша система защиты фиксирует четыре неудачных попытки входа под одной учетной записью. Это явное нарушение, поскольку у нас в политике предусмотрено ограничение в три попытки. Для обнаружения четырех и более неудачных попыток не требуется машинное обучение. Активность одной учетной записи из разных географических точек в течение одних суток может означать вредоносную активность. А может и нет, если вы, например, полетели в командировку и заходили в защищаемую систему, скажем, из аэропортов Москвы, Лондона, Нью-Йорка и Чикаго. Такие сценарии банки часто считают мошенничеством, блокируя соответствующие карточные транзакции. Для обнаружения подобной активности также не требуется машинное обучение. А вот для доступа из непривычного места уже понадобится. Потому что мы заранее не знаем, какое место является привычным, а какое – нет. Здесь и поможет обучение без учителя и один из его алгоритмов – кластеризация, которая позволяет объединять схожие события кластеры. Появление нестандартного места входа (не попадающего в кластеры) является аномалией и может служить сигналом кражи учетной записи. Данный подход бывает менее точен, чем обучение с учителем. Так, в вышеприведенном случае может оказаться, что это даже не кража учетной записи, а пользователь дал добро какому-то приложению через OAuth подключаться к защищаемой системе (в частности, к облачному хранилищу) и благополучно забыл об этом.
Другой сценарий, где хорошо срабатывает обучение без учителя, – обнаружение утечек информации или саботаж администратора. Вы не можете сказать, где провести грань между нормальным и аномальным числом удаляемых из облака или скачиваемых по локальной сети на один компьютер файлов. У вас есть возможность только сравнивать между собой этот признак у разных пользователей и групп пользователей, объединяя их в кластеры и выявляя тем самым нормальное и аномальное поведение. Допустим, обычно пользователи в день выгружают в Интернет около 100 Мбит данных, но в один из дней, какой-то пользователь выкачал более 10 Гбит. Это явная аномалия, определяемая и без машинного обучения. Однако машинное обучение нам поможет объединить несколько признаков (например, объем данных, время, протокол, тип данных, адрес получателя) и отделить выгрузку дистрибутива новой версии приложения для удаленных офисов от кражи данных.
Нейросети – это тоже один из видов алгоритмов машинного обучения без учителя, которые в последнее время получают все большую популярность. Обычно они применяются там, где достаточно сложные датасеты (изображения лиц в биометрии, а также голос или изображения документов) или трудно выделить признаки, которые будут выбирать модель в датасете. Ключевая идея нейросети – возможность внутренним ее слоям делать собственные суждения о том, что важно в датасете и что должно быть извлечено из него в процессе обучения. Все вышеописанные примеры могут быть обнаружены нейросетями, но обычно их используют в более сложных сценариях – распознавание фальшивых документов, борьба с угрозами для биометрии, поиск утечек информации в голосовых коммуникациях, распознавание текстов по безопасности и т. п. Одним из серьезных недостатков нейросетей можно назвать отсутствие обратной связи, то есть невозможность объяснить, почему из входных данных получился именно такой результат.
Заключение
Современная информационная безопасность сталкивается с рядом сложностей, среди которых следует назвать огромные потоки событий, снижение экспертизы и нехватку персонала. При этом число атак растет, несмотря на принимаемые меры защиты. В настоящее время средний период необнаружения угроз составляет около 200 дней, что становится результатом реактивности используемых защитных средств. Поэтому сегодня, как никогда, важно применять новые методы борьбы с вредоносной активностью, самым перспективным из которых представляется машинное обучение.
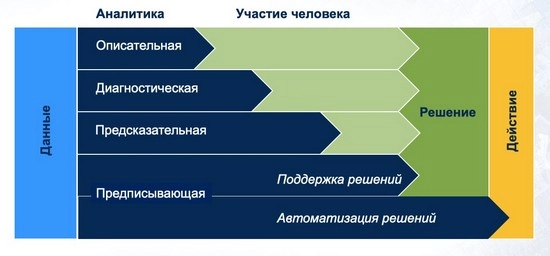
Да, пока мы не достигли того уровня, чтобы полностью отказаться от участия человека в принятии решений в области кибербезопасности. Абсолютное большинство разработанных сегодня моделей позволяет нам детектировать новые угрозы, аномалии и подозрительные действия, отвечая на вопросы «что случилось?» и «почему это случилось?». Пока мы почти не умеем предсказывать будущее в ИБ (исключая некоторые узкие сферы), а потому вопрос «что случится?» остается без ответа. И уж тем более мы не знаем, как ответить на вопрос «что я должен сделать?» (предписывающая аналитика, которая является уделом будущего).
За последние шесть лет на рынке кибербезопасности было зафиксировано свыше 220 поглощений, связанных с искусственным интеллектом. Это направление в настоящий момент входит в пятерку самых распространенных сделок, а многие игроки (исключая, пожалуй, отечественных) рынка ИБ активно инвестируют в технологии машинного обучения, интегрируемые в свои продукты. Но конечный потребитель в массе своей пока не может активно воспользоваться всеми преимуществами искусственного интеллекта – у него нет для этого ни правильно обработанных датасетов, ни, что самое важное, квалифицированных аналитиков данных, способных самостоятельно разработать или применить существующие модели анализа. Однако даже для того, чтобы пользоваться моделями машинного обучения в приобретаемых или эксплуатируемых решениях, необходимо понимать, что представляет собой данная технология.
Однако следует помнить, что машинное обучение не панацея. Во-первых, существует целый класс атак на него, направленных как на датасеты, так и на сами алгоритмы, что может привести к неверным решениям, пропущенным атакам или ложным срабатываниям. А во-вторых, злоумышленники тоже начинают применять методы машинного обучения в своей криминальной деятельности – создании вредоносных программ, анализе поведения пользователей, разработке ботов-сборщиков персональных данных, поиске уязвимостей, фишинге, подборе паролей, подмене личности, обходе систем защиты и т. п. И противопоставить таким злоумышленникам можно только искусственный интеллект. Поэтому применение машинного обучения в информационной безопасности – необходимость, без которой современную систему кибербезопасности представить невозможно.
Опубликовано 31.10.2018
