







Как не дать серверу «упасть»

Почему важен правильный выбор конфигурации сервера
В каких случаях стоит переплатить, но гарантировать избыточность
Зависит ли надежность сервера от установленного софта
Все, что может испортиться, портится.
Следствие: все, что не может испортиться, портится тоже.
Первый закон Чизхолма.
Почему важен правильный выбор конфигурации сервера
Не зря я вынес в эпиграф первый закон Чизхолма – он лучше любого многословного трактата объясняет, почему надо уделять много внимания обеспечению отказоустойчивости серверов. Нет, разработчики не обманывают: серверное оборудование действительно затачивается под специфику применения: и работу круглосуточную, и нагрузки «потолочные», и условия жесткие. Но не стоит забывать, что производитель – прежде всего бизнесмен, а стало быть, ему тоже приходится балансировать на грани необходимого качества и разумной стоимости продукта, в силу чего считать последний образцом надежности вряд ли возможно.
Военные или космические эксперты, скорее всего, даже и близко не подпустили бы такое оборудование к своим испытательным стендам, но у них и запросы другие. Так что условимся: мы имеем дело с бытовой техникой, а она, как и всякий ширпотреб, позволяет себе отказывать. Реже, чем типовой ПК, конечно, но все же достаточно часто. Особенно, когда потребитель умудряется усугубить ситуацию за счет выбора неправильной конфигурации: сознательно упрощает требования к конструкции и, в частности, отдельным ее узлам, а в итоге недоумевает: как же так, отдал деньги за настоящее серверное железо, а оно сломалось! Ну и что, что дешевое и впритык, так ведь серверное же!
Вот здесь-то и кроется источник проблемы. В первую очередь надо выбирать такие узлы и компоненты, которые соответствуют выполняемым задачам, работая при этом максимум на 70-80% нагрузки. А лучше – на 50-60%. Для сравнения представьте себе, что нужно перевезти груз весом в тонну, а в наличии только «Жигули» и «Газель»: довезут обе, но у которой из них больше шансов не доехать до места назначения?
Иными словами, экономия средств на серверном оборудовании оправданна только тогда, когда этому есть разумное обоснование. Причем техническое – а не порожденное жабой-самодавкой главбуха или руководителя.
В каких случаях стоит заплатить больше, но гарантировать избыточность
Надежность работы любого устройства определяется только резервированием (дублированием) критичных компонентов. С одной стороны, такая избыточность ведет к дополнительным расходам, но если подсчитать ущерб от утери критически важных данных и/или простоя отказавшего сервера, эти затраты уже не видятся столь чрезмерными. Резервируется не все подряд. Наиболее отказоустойчивые компоненты – это материнская плата, процессоры и оперативная память. А вот все механические узлы (система охлаждения, жесткие диски) требуют обязательного резервирования.

Корзина для дисков с горячей заменой позволит обойтись без прерывания работы сервера, даже если потребуется сменить вышедший из строя накопитель. Впоследствии RAID-контроллер автоматически включит новый HDD в состав массива
И если с жесткими дисками обычно вопросов не возникает (все понимают, что на них хранится информация), то на системе охлаждения частенько стараются сэкономить. И очень зря: любая проблема в ее работе приведет к неминуемому отказу даже таких условно надежных узлов, как материнская плата и память (о процессорах тактично умолчу – они могут себя защитить от перегрева). Поэтому, приобретая сервер, лучше озаботиться не только наличием возможности горячей замены вентиляторов без остановки системы, но и приобрести в запас несколько кулеров, тогда процесс замены отказавшего займет считанные минуты и никак не скажется на общей надежности системы.

Специальный кулер "под горячую замену" при определенной сноровке можно заменить за несколько секунд, не останавливая сервер
Аналогичная история с источниками питания. Привычка оценивать потребности исходя исключительно из потребляемой мощности в корне неверна. «Зачем мне два БП по 750 Вт, если максимальная потребляемая мощность всего оборудования при этом не должна превышать 400, а в моем случае и 300 не наберется?» – рассуждает неискушенный покупатель, и, пожав плечами, сборщики комплектуют ему сервер одним 500-Вт БП. Нет слов, какое-то время он проработает, но все равно откажет. И тогда в лучшем случае это выльется в потерю времени на поиск, покупку и установку нового или ремонт старого, а в худшем – выйдут из строя другие компоненты и ситуация будет критической, с необратимой потерей информации. Разумеется, все это время сервер будет простаивать, данные окажутся недоступными, а работа организации – парализованной. Этого не произойдет, если в сервере установлены два источника питания: вышел из строя один – работа продолжится с питанием от второго, а сломавшийся уедет в сервис. Вероятность, что за время ремонта из строя выйдет и второй, уже небольшая.

Дублированные источники питания с горячей заменой - идеальное решение для систем высокой надежности, - их замена выполняется без отключения сервера.
Что касается жестких дисков, тут без контроллера RAID и, соответственно, RAID-массива не обойтись. Распространенное заблуждение: мол, «для наших нужд вполне хватит и встроенного (программного), зачем еще и дискретный», – приводит к тем же проблемам, что и в случае с БП. Конечно, можно выкрутиться, обеспечив горячую замену жестких дисков и построив схему «зеркало» (RAID 1) или 0+1, в этом случае шансы на фатальный исход снижаются. Правда, при такой организации массива количество дисков увеличивается вдвое и соответственно возрастает цена, но не настолько, чтобы стать критичным параметром.
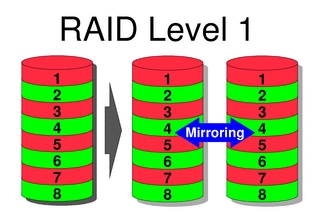
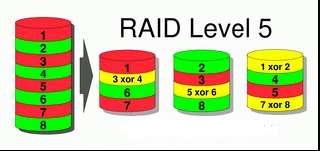
RAID-массив первого уровня требует полного дублирования дисков в системе, что существенно дороже, чем массив пятого уровня. Но для создания такого массива потребуется минимум три диска, тогда как для RAID1 достаточно двух.
Если данные имеют высокую важность (особенно когда речь идет о базах данных организации и коллективной работе с ними), тут уж не до шуток: приобретение аппаратного RAID-контроллера с батарейной защитой кеш-буфера, а также применение горячей замены обязательны к рассмотрению. Разумеется, и сами винчестеры надо брать серверные: в отличие от обычных (бытовых), они не только более надежны (что обеспечивается тщательным отбором комплектующих на этапе изготовления), но и адаптированы для работы в составе RAID-массива. Кстати, в этом случае есть возможность существенно снизить избыточность дисковой подсистемы, применив RAID-массивы уровней 5, 5Е, 6 или 6Е (критический отказ в таком решении маловероятен). Конечно, можно обеспечить и еще более высокую надежность, установив два контроллера RAID и организовав матричную схему для хранилища данных, но это уже чрезмерный вариант для одного сервера, допустимый только при насущной необходимости (например, если требуется работа сервера по схеме «24×7×365» с перерывами не выше нескольких минут в год).

Дополнительный батарейный модуль, подсоединяемый к контроллеру RAID, существенно повышает надежность подсистемы хранения данных.
Обязательно стоит предусмотреть варианты замены сетевой подсистемы. Редко, но они тоже подвержены поломкам, и тогда вполне работоспособный сервер становится недоступным. Наличие всего одной дискретной сетевой платы, установленной в корпусе дополнительно к интегрированной, позволит быстро восстановить доступ к серверу (если, конечно, сисадмин заранее озаботился ее подключением к локальной сети и внес правки в схему маршрутизации). Дополнительную защиту от отказов и сбоев обеспечат источники бесперебойного питания, причем модели типа on-line (только они способны гарантировать максимально качественное выходное напряжение). Дублировать их можно, но не обязательно, достаточно иметь на подмену более простое решение аналогичной мощности. Хотя самый лучший вариант – два одинаковых ИБП, сменяющих друг друга при необходимости проведения профилактики (учитывая качество отечественной сети энергоснабжения, пытаться сэкономить на ИБП – себя обмануть).
В завершение разговора о повышении надежности работы аппаратной составляющей добавлю, что размещать сервер необходимо в отдельном помещении, в предназначенной для этого вентилируемой стойке, а не рядом с кучей хлама. Отсутствие пыли и наличие кондиционера существенно продлевают жизнь оборудованию.
Зависит ли надежность работы сервера от установленного софта
Вопрос стабильной и надежной работы оборудования, безусловно, важен, но, даже решив все задачи по резервированию, можно свести на нет все затраченные усилия, не уделив должного внимания программному обеспечению. Как показывает статистика, более половины отказов и сбоев обусловлены именно некорректной работой ПО (если, конечно, не принимать во внимание человеческий фактор).
К сожалению, настройка современных программных продуктов, начиная от ОС и заканчивая прикладными средствами управления, дело очень сложное, требующее специальных знаний. А о покупке самого продвинутого и защищенного железа с последующей экономией на программном обеспечении (читай: установкой нелицензионного софта) я и упоминать не хочу. Поговорим лучше о том, как защитить сервер от «падения» по причине сбоев в работе программных средств.
Первая и главная задача – не допустить установки на сервер ничего лишнего. Поскольку мы ведем речь о надежности, следует вспомнить один важный постулат: «Общая надежность системы определяется надежностью ее самого ненадежного компонента». Ну и вдобавок: «Вероятность отказа прямо пропорциональна общему количеству точек отказа». Применительно к нашей теме можно сказать так: чем больше в систему напихано всякого ПО, тем ниже ее надежность. В идеале каждый сервер должен выполнять исключительно свою функцию: например, на сервере БД должны быть установлены только ОС, СУБД и минимум средств контроля и системных утилит.
Практика подтверждает: специализированные системы работают безотказно годами, тогда как серверы типа «все-в-одном» – до первого сбоя. Конечно, идеала достичь трудно и лучше всего исходить из принципа разумной достаточности: кроме обязательных компонентов и драйверов на сервере должны быть установлены только средства мониторинга и удаленного управления, а также комплекс антивирусной защиты (если последняя задача не решается централизованно).
Выбор операционной системы – тоже сложный вопрос. Надо помнить одно: не существует сверхстабильных универсальных ОС, прекрасно работают как решения на базе Windows, так и разнообразные версии Unix. Главная задача, которую требуется решить, – специализация персонала, обслуживающего сервер. Если ваш сисадмин специализировался на Windows, то не стоит заставлять его в срочном порядке осваивать Linux только потому, что он бесплатный – выйдет дороже. Впрочем, это относится более к человеческому фактору, нежели к надежности ПО. Последнее определяется исключительно совместимостью с аппаратными узлами, а также применением самых свежих обновлений и выполнением рекомендованных профилактических операций.
В системах повышенной надежности не допускается использование альфа- и бета-версий – только стабильная сборка (даже если в бете есть очень нужные нововведения, следует дождаться финального релиза). Категорически запрещается применять разного рода «улучшители», «ускорители» от сторонних разработчиков – это может быстро привести к краху системы.И наконец, залог долгой беспроблемной работы программного обеспечения – правильная установка и настройка, а значит, эту операцию для серверов должны выполнять исключительно авторизованные специалисты.
Если до сих пор мы говорили об обеспечении надежности системы в целом, то сейчас пора остановиться на одном очень важном способе обеспечения функционирования серверов – резервировании текущего состояния. Создание резервной копии работоспособной конфигурации системы позволяет в случае любого сбоя быстро восстановить ее в случае серьезного сбоя. Операция проводится в несколько этапов. В первую очередь обязательно делается слепок (образ) установленной, настроенной и отлаженной операционной системы, Причем делается однократно и сохраняется на случай если потребуется вернуться к «чистой» ОС.
Средства архивирования и восстановления системы, такие, как Symantec Backup Exec, позволяют сохранить все важные данные и быстро восстановить их на любом этапе в случае критического сбоя системы или неудачного обновления ПО.
Следующий важный бэкап – полностью настроенный и запущенный в работу сервер со всем необходимым ПО и компонентами (также однократный). Впоследствии резервные копии создаются по какой-либо из стандартных схем с соблюдением периодичности: ежемесячные, еженедельные, ежедневные, причем чаще всего сохраняются исключительно изменяющиеся данные. Дополнительные резервные копии обязательно создаются перед внесением обновлений или критичных изменений системы и программных продуктов, что позволяет в случае неудачи (или нестабильной работы) вернуться к предыдущему, полностью работоспособному состоянию.
Резервные копии следует хранить в надежном месте, которое предполагает возможность быстрого доступа для восстановления. Часть информации можно (и нужно) размещать на внешних носителях: жестких дисках, оптических накопителях, флеш-картах. Эффективным считается наличие специализированных серверов, предназначенных только для целей хранения резервных копий (бэкап-серверов).
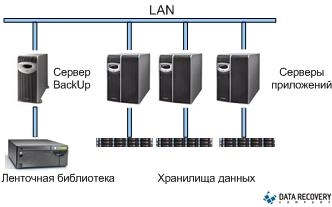
Один из вариантов решения системы централизованного хранения данных - выделенный backup-сервер и сброс данных на внешнее хранилище (ленточный накопитель, например)
Так, стартовый образ системы или полностью настроенного ПО лучше всего хранить на автономном носителе и соответственно держать последний в надежном месте. А вот текущие копии данных и прочие архивы удобно хранить на бэкап-сервере, периодически сливая с него информацию на те же оптические диски. Такая схема позволит в любой момент быстро и без проблем восстановить работоспособность сервера и его сервисов после сбоя. Да и обходится она недорого благодаря обороту носителей и небольшим расходам на оборудование (в качестве бэкап-сервера чаще всего используют относительно недорогие системы).
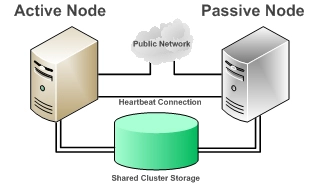
И в заключение нельзя не упомянуть о дорогостоящей, но весьма эффективной схеме резервирования посредством кластерных решений. Кластер представляет собой два однотипных сервера с одинаковой конфигурацией, работающих в паре. В отказоустойчивых решениях наиболее применима схема active-passive, которая предполагает синхронизацию данных в реальном времени: в нормальном режиме в ней работает только один сервер (активный), а второй (пассивный) просто поддерживается копией состояния активного и включается в работу, как только происходит сбой (или активный сервер сообщает о другой причине, требующей замены). В сочетании с вышеописанными действиями по обеспечению отказоустойчивости серверов кластеры считаются идеальным вариантом, о чем говорит их повсеместное применение в высоконадежных системах хранения данных. Правда, о том, что это недорогое решение, говорить не приходится: характеристика «качественно и недорого» в данной сфере неприменима – слишком высока цена утраты данных.
Опубликовано 14.09.2011