







Системы распознавания текста под Linux

В наше время обычному пользователю нет необходимости распознавать отсканированные тексты офлайн – все делопроизводство давным-давно ведется в цифре. Однако если такая потребность возникнет, реализовать ее нужно срочно. Желательно вчера. Что делать в таком случае юному линуксоиду?
Расскажу одну историю. Помнится, начиналось все чинно-благородно. Дед Мороз прибывший к нам на праздник прямиком с детского утренника, с выражением читал детские письма, и некоторые чувствительные дамы одобрительно кивали в знак согласия со всеми требованиями малолетних вымогателей. Тем временем Снегурочка развлекала народ конкурсами и одаривала конфетами в награду за участие в них. Ну а благодарные зрители весело уминали салатики, жевали бутерброды с «настоящей» черной икрой (по 50 рублей за 200 грамм в ближайшем магазинчике) и запивали все это клюквенным морсом. Ничто не предвещало беды.
Подозреваю, что основной причиной дальнейших событий стали те самые шоколадные конфеты, подаренные Снегурочкой, – скорее всего, они были просроченные. Впрочем, многое как в тумане. Помню только, что борода у Деда Мороза была белая и длинная, а потом стала короткая, рыжая и кудрявая и сам он стал похож на эрдельтерьера в красной шапочке. А Снегурочка, начав праздник молоденькой застенчивой блондинкой в кокошнике, ближе к финалу щеголяла с выбритым виском и фиолетовой шевелюрой. Еще они вместе орали: «Панки, хой!» и вели себя очень неприлично. Мы все решили, что эту парочку попросту подменили.
Короче, третьего января я очнулся в постели с дичайшей головной болью и твердой уверенностью, что во всем виноват вирус гриппа, который я мог подхватить от Снегурочки – она на меня дышала как-то подозрительно. И, когда ртутный градусник показал 35 С°, стало ясно: болезнь берет свое и времени осталось мало, нужно успеть уладить незаконченные дела до того момента, пока моя тушка не остыла совсем и не приняла температуру окружающей среды. Первым делом решил утрясти финансовые вопросы.
.jpeg)
«Главному редактору журнала “IT-Expert”. Я, Храмов Евгений, находясь в нетрезвом уме и нетвердой памяти, прошу Вас все невыплаченные мне гонорары перевести в фонд помощи престарелым LOLCODE-программерам. 30 сребреников, которые я, если верить слухам, должен был получить за обзоры отечественного ПО и ОС, прошу вложить в дальнейшую разработку российского программного обеспечения (подпись)».
После создания сего шедевра эпистолярного жанра встал вопрос: как отправить его адресату? Классический вариант с почтовым голубем был отклонен по причине банальности, а более прогрессивная пересылка Почтой России – по причине чрезмерных рисков. Усталый мозг наконец выдал единственно верный ответ: отправить e-mail, или, как выразился неведомый мне гений, электропочтой.
Конечно же, отправлять простенький скан было не совсем удобно. Во-первых, кто там будет разбираться в моих бледных каракулях? Во-вторых, всегда есть возможность описки, а это не очень хорошо – все, что было заработано честным и нечестным трудом, пойдет прахом! Про все долгосрочные инвестиции и надежды на многомиллионные доходы можно будет забыть. Следовательно, необходимо продублировать документ в более удобном для чтения формате. Распознать отсканированный текст и добавить к телу письма показалось неплохой идеей. А зря...
…Через пару-тройку часов, проведенных в проверках работоспособности и сравнения характеристик, на первый план вышли два варианта: CuneiForm и Tesseract. Обе разработки предназначены для оптического распознавания текста.
История Tesseract началась еще в восьмидесятых годах прошлого столетия. Разработчики из Hewlett-Packard, наверное, и не ожидали столь долгого жизненного пути своего детища – спустя 40 лет система Tesseract вполне способна распознавать тексты, написанные более чем на сотне языков мира. Благодарить за это нужно руководство компании, которое сделало общедоступными исходники программы в 2005 году, и корпорацию Google, которая с 2006 года поддерживает дальнейшую работу над OCR Tesseract.
В свою очередь OCR CuneiForm не так монументальна – ей «всего-то» около 30 лет. Однако, говоря о OCR-системах, не упомянуть ее невозможно, – это один из первых успешных проектов в постсоветской России. Разработанная маленькой скромной Cognitive Technologies, OCR CuneiForm уже в 1994-м использовалась в сканерах Hewlet-Packard. А в 1995-м Epson заключила контракт о комплектации своих сканеров этой системой. Да что там говорить, культовый CorelDraw еще в 1993 году включал в себя библиотеку распознавания текста Cognitive. С той поры прошло достаточно времени и уже вряд ли у кого повернется язык назвать создателей CuneiForm «маленькой компанией» – сегодня это лидер в разработке решений для беспилотного управления транспортом и техникой.
В 2008 году исходные тексты CuneiForm были опубликованы под лицензией BSD, что позволяло независимым программистам улучшать и поддерживать ПО в рабочем состоянии. Судя по всему, через несколько лет интересы сообщества изменились, и на сегодняшний день последней датой обновления CuneiForm for Linux указан апрель 2011-го.Для того чтобы оценить возможности распознавания текста в Tesserasct и CuneiForm, решено было воспользоваться GUI-приложением OCRFeeder. Оно позволяет выбирать предпочтительную систему, управлять ею и просматривать окончательный результат, используя графический интерфейс, понятный любому пользователю.
Для установки в Ubuntu и производных от нее достаточно ввести в терминале несколько команд:
sudo apt update,
вводим пароль sudo,
sudo apt install ocrfeeder.
Для тех, у кого темный экран терминала вызывает жгучее неприятие, есть еще более простое решение: запускаем менеджер приложений и в поисковой строке вводим аббревиатуру OCR. Обычно приложение появляется в списке и предлагается к установке.
.png)
Оказалось, что вместе с приложением устанавливается только движок Tesseract, и, как выяснилось далее, для этого есть веские причины. Пока же добавим к нему CuneiForm:
Sudo apt install cuneiform
.png)
Интерфейс приложения прост до примитивности. В меню «Файл» выбирается необходимая опция и загружается изображение. Мышкой можно выделить область, которую необходимо распознать. Справа от текста находятся меню выбора системы OCR и клавиша «Распознать», запускающая процесс.
Идеальное изображение
На следующих фото можно сравнить результаты работы с качественным изображением. Образец для теста, напечатанный кириллицей, выбран с определенной целью. Прежде всего кириллический алфавит наиболее часто использовался и используется в любых документах на территории нашего государства и велика вероятность, что именно его придется распознавать. Вторая немаловажная причина – локализация. У англоязычных пользователей все может быть замечательно, но это не означает отсутствия проблем у других.
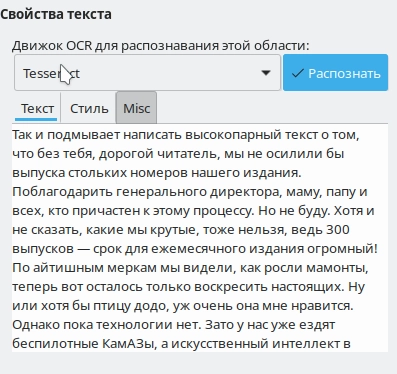
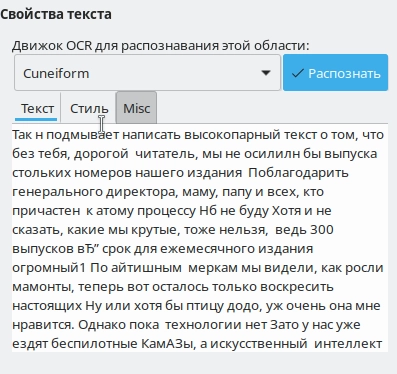
Как видим, при идеальном изображении (без каких-либо артефактов, пыли, грязи и оптических искажений) Tesseract верно распознал 100% текста. С CuneiForm ситуация иная – есть ошибочные символы и неточности, все-таки десять лет без поддержки дают о себе знать. Вполне возможно, за столь долгий срок сменились и сами алгоритмы распознавания текста. В любом случае при использовании качественного изображения у нас получилось распознать весь текст вместе со знаками препинания без каких-либо ошибок.
Сканы низкого качества
Какой результат мы получим, если исходное изображение будет с низким разрешением, мусором и оптическими искажениями? В качестве примера можно использовать лист из отсканированных вручную СНиПов (строительных норм и правил).
.png)
.png)
Как видим, Tesseract сработал без ошибок, текст отформатирован, знаки препинания и спецсимволы распознаны верно. CuneiForm же в распознанном тексте не оставил форматирования – весь текст слипся в один кусок, многие символы подменены другими, а дефис и вовсе заменен на неизвестные кракозябры.
Видимо, это и есть основная причина, по которой OCRFeeder по умолчанию устанавливается только с движком Tesseract. Для чего искать что-то еще, если имеется отличный и полностью рабочий вариант? С такими мыслями я и приступил к распознаванию документа, написанного от руки.
Распознавание рукописного текста
Как ни печально сознавать, но завышенные ожидания наивного юноши не оправдались. Совсем. То, что появилось на мониторе, я и сам-то прочитал с большим трудом.
.png)
CuneiForm после долгих размышлений вынес лаконичный вердикт всей смысловой нагрузке документа – «ОЮ». Tesseract добавил к этому, видимо, что-то о моей скромной персоне: «ГлАвно.ла редее 9 И меррноа. ГОТ».
Ну что же, гот так гот. Спорить с искусственным интеллектом себе дороже. Поэтому замечательную идею распознавать рукописные тексты в Linux пришлось отложить на неопределенный срок.
Выводы
Итак, на что можно рассчитывать, устанавливая OCRFeeder в Linux? В конечном итоге мы имеем вполне комфортный графический интерфейс, позволяющий любому пользователю загружать, распознавать и импортировать печатные тексты. Свободная лицензия приложения допускает использование его в коммерческих целях без требования каких-либо выплат, подписок и ограничений. Кроме того, оно позволяет работать офлайн, не требуя выгрузки конфиденциальных данных в Сеть. Такой вариант ПО подойдет как для личного необременительного использования, так и для больших тяжеловесных проектов в офисе.
P. S. Процесс установки OCRFeeder можно использовать как средство для нормализации температуры и отвлечения внимания больных простудой и ОРЗ. В моем случае это сработало.
Опубликовано 01.03.2021