









Искусство PILOTирования
Автор
Николай Вяткин

Тысяча тестов, сто дней интенсивной работы, десять ручьев пота и – достойный результат.
Тысяча тестов, сто дней интенсивной работы, десять ручьев пота и – достойный результат. Проведено достаточно много исследовательской работы, сломано немало копий, обнаружены интересные факты. Пожалуй, это был уникальный в своем роде проект, ведь не каждый день доводится сравнивать технологии последнего поколения на площадке собственного ЦОДа. Именно об этом я и хочу рассказать. Надеюсь, описанный мною опыт найдет применение и в ваших проектах.
Если сейчас меня спросить, что послужило «драйвером» этого проекта, я отвечу однозначно – неизбежность грядущих перемен, связанная с «бизнесом». Бизнес-среда в которой мы с вами работаем, пребывает в состоянии перманентного развития: перемены связаны и с выводом новых продуктов, изменением конкурентной ситуации, и с повышением эффективности бизнес-процессов, снижением затрат и т. д. Все это так или иначе ведет к трансформациям внутри компании, а значит – и в ИТ. Технологии устаревают, «железо» не справляется с новыми нагрузками, системы растут, и в какой-то момент мы в ИТ оказываемся перед выбором: по какому пути двигаться дальше?
Что нас ждет в «светлом будущем»?
Однажды такой вопрос встал и перед нашей командой. Картина будущего рисовалась грандиозной как с точки зрения бизнеса, так и в плане ИТ-ландшафта. Проведя ретроспективный анализ и построив аппроксимацию на пять лет вперед, мы увидели, что речь идет не о десятках терабайт данных, а, возможно, о сотнях.
В результате исследования выяснилось несколько важных особенностей. Так, все системы строились по классическому принципу: каждая состояла из трех логических узлов (серверов приложений, серверов баз данных и систем хранения) и использовалась объектно-реляционная система управления базами данных. На тот момент все бизнес системы работали на довольно «свежих» RISK-машинах, объединенных в кластеры с балансировкой нагрузки и mid-range СХД. Как выяснилось, такая архитектура, с точки зрения перспектив дальнейшего развития, имела ряд серьезных ограничений.
При росте нагрузки серверы приложений масштабируются добавлением инстанций, сервер баз данных — добавлением оперативной памяти и процессорной мощности, рост объема данных приводит к увеличению дисковой памяти в СХД. С серверами приложений все хорошо, нагрузка на них повышается линейно. Получается, что основные проблемы лежат в области обработки данных.
Во-первых, сервер баз данных один и принимает на себя всю нагрузку cо всех серверов приложений.
Во-вторых, нагрузка на сервер здесь увеличивается нелинейно, поскольку происходит это одновременно в двух измерениях: а) рост бизнеса ведет к увеличению объема данных, обрабатываемых внутри систем, б) каждый новый пользователь в течение рабочего дня создает дополнительную нагрузку, формируя рабочие задания.
И последнее: СХД тоже является узким местом, что показали и замеры, и наши тесты. Когда в качестве эксперимента мы поставили вместо нашей СХД дисковый массив на Flash-носителях, получился значительный прирост производительности. В некоторых системах серверы баз данных стали обрабатывать запросы на 30% быстрее за счет того, что треть процессорного времени уходила на ожидание ответа от СХД. Поэтому мы пришли к выводу :что подход линейного наращивания мощностей текущей архитектуры не решит наших задач.
Все равны, но некоторые равнее
Конечно же, нас мучил вопрос: все ли наши бизнес-системы в одной лодке? Выяснилось, что нет. Моделирование показало, что нагрузка на системы будет расти по-разному, так как не все параметры линейно зависят от масштаба бизнеса. Например, объем базы данных системы управления складами, как правило, увеличивается пропорционально не числу складов, а числу товарных позиций. А в системе CRM база данных растет пропорционально количеству клиентов, но количество бизнес-пользователей при этом может оставаться почти неизменным. Все это показывало, что каждая система имеет индивидуальную скорость развития, поэтому мы разбили их на группы классического ABC-анализа и в качестве критерия взяли лидеров по прогнозному объему данных: А — самые крупные системы (80% всего объема данных), В – средние (15%) и С – малые (оставшиеся 5%). В группу А попали две системы: EPR и корпоративное хранилище, на базе которого строится отчетность. Не то чтобы для нас это стало открытием, но сложилось четкое понимание, что в перспективе картина не изменится и баланс между системами будет похож на текущую ситуацию.
Разведка боем
Помните картину Васнецова «Три богатыря»? Нечто подобное представляла собой и наша группа перед поиском решения поставленной задачи. Посовещавшись, решили провести «разведку боем», то есть выбрать несколько возможных решений и развернуть масштабный пилотный проект, предполагающий их сравнение.
Во-первых, одно дело – маркетинговые сказки, и совсем другое — реальный тест на продуктивных данных в условиях, приближенных к боевым. Во-вторых, хотелось сопоставить решения, чтобы предпочесть действительно лучшее.
Естественно, прежде чем тестировать, надо понять, что это будет. Учитывая наши объемы данных, решения, которые могли нам подойти, лежали в секции Leaders магического квадранта Гартнера по системам управления базами данных. Предварительно мы исследовали решения всех лидеров рынка, в том числе EMC Green Plum, Tearada, SAP HANA, несколько систем от вендоров Oracle и IBM и др. В конечном итоге в шорт-лист попали две системы: In-memory решение, которое обрабатывает данные в памяти «на лету» и мощная «молотилка» баз данных. О методе их сравнения и пойдет речь. Итак, что же у нас получилось?
Лицом к лицу
Сопоставить две технологии, представляющие собой не просто ПО или «железку», а высокотехнологичное программно-аппаратное решение, включающее в себя серверы, СХД, коммуникационное оборудование и другие технологические ноу-хау и специализированное ПО, не такая простая задача, как кажется на первый взгляд.
Приведу простой пример. Мы планировали взять наиболее часто используемые отчеты и произвести замеры времени их выполнения на трех стендах (копия нашего «продуктива» и два новых решения), а затем сравнить результаты. Выяснилось, что системы управления базами данных обладают достаточно емким кешем, а некоторые – кешем из нескольких уровней, и после первого прогона тестов данные уже лежат в памяти. Второй прогон без изменения параметров запуска приведет лишь к обращению в память кеша. Другой пример: продуктивные системы постоянно находятся под нагрузкой. Выполнение заданий на ненагруженной системе или системе, нагруженной иным образом, покажет искаженный, заведомо лучший результат, несопоставимый с продуктивной системой, в чем мы убедились на собственном опыте. В результате поняли, что тестирование должно быть более технологичным, по сути говоря, следовало воссоздать на стендах нагрузку, идентичную продуктивной. Как вы понимаете, подключить тестовые стенды к работе с реальными данными мы не могли, поэтому стали изобретать свою методику.
Частота и интенсивность. В первую очередь частота запуска отчетов должна быть пропорциональна частоте в реальной системе. Для этого мы проанализировали статистику вызовов отчетов за полгода и выбрали самые интенсивные. Некоторые отчеты вызываются редко, но строятся часами, другие обрабатываются минуту, но вызываются тысячи раз в день разными пользователями. Поэтому в качестве показателя интенсивности было выбрано суммарное время выполнения отчета за полгода, независимо от того, с какими параметрами он был запущен.
Операционный день. Моделирование должно было повторить наш операционный день. Обычно он делится на две части: днем работают пользователи, ночью – регулярные фоновые задания, поэтому был построено два профиля: дневной и ночной. Чтобы представить это наглядно, приведу реальный график нагрузки CPU с одного из серверов приложений. На нем явно видны тренд пользовательской активности и ночные фоновые задания. Ну а чтобы картина стала максимально достоверной, помимо основных профилей, дополнительно был создан фон или, если хотите, «шум», связанный с тем, что на сервере в этот момент происходят другие параллельные операции, и фон позволил сымитировать подобную нагрузку.
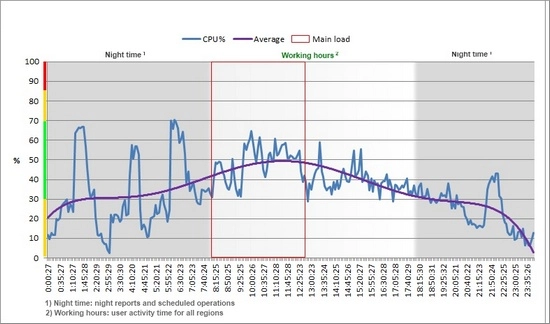
За основу построения дневного и фонового профиля была взята статистика по наиболее нагруженным дням месяца.
Масштабирование. Как вы понимаете, задача стояла не только посмотреть, как будет вести себя система в текущей ситуации, – необходимо было проверить масштабируемость испытываемых решений. И мы разработали специальные нагрузочные тесты с повышенной пользовательской активностью и профили с увеличенным объемом данных в два, три и пять раз.
Результаты. Для нас важно было не только сравнить количественные показатели, но и оценить качественные характеристики, поэтому, помимо замеров времени отклика, мы также снимали профили нагрузки по CPU, I/O, LAN и т. п. со всех компонетов инфраструктуры и проводили качественный анализ и интерпретацию полученных данных. В итоге мы получили большой объем статистики, различные графики, сведения о параметрах баз данных и «железа».
Разработка методики оказалась не такой простой, как казалось вначале. Тот вариант, который очень кратко описан на одной страничке, на самом деле является результат месячной работы и представлен в 50-страничном документе, а полный отчет занял 100 страниц текста, 50 Excel-таблиц и 200 графиков.
За кадром
Когда читаешь о проектах, всегда возникает желание заглянуть за кулисы. Ведь не может все быть идеально. Поэтому мне хочется поделиться тем, что осталось за кадром.
Первая проблема, с которой пришлось столкнуться, — для тестирования нам не смогли предоставить решения достаточной емкости, поэтому объем данных пришлось снизить в 2,5 раза. В итоге прибавилась неделя дополнительной работы.
В результате тестирования «передовых технологий» на одном из серверов вышла из строя материнская плата, что повлияло на сроки тестирования уже самого решения.
Поскольку часть оборудования ввозилась из Европы, тут мы столкнулись с реалиями российской таможни, Велись переговоры по поводу использования HP Load Runner. номы пошли по другому пути. Вместо дорогого ПО мы обратились к JMeter — почти бесплатному инструменту для нагрузочного тестирования, и он нам полностью подошел.
Когда встал вопрос, кто будет разрабатывать методику и нагрузочные скрипты, ни один из подрядчиков, разворачивающих стенды на нашей площадке, не смог предложить серьезную методику тестирования, подходившую под наши требования. Если бы не случайная встреча с Performance Labs, скорее всего, так и не удалось бы своими силами реализовать серьезное тестирование из-за отсутствия опыта в подобных проектах. На одном из стендов пришлось три раза прогнать полный цикл всех тестов, что потребовало ни много ни мало пяти суток. И каждый раз выявлялись какие-то нюансы: неудачная версия прошивки (после ее замены все стало работать вдвое быстрее), плохо настроены балансировки между серверами и т. п.
Во всем проекте, с учетом проведенных тендеров, работа велась с 17 контрагентами. Вендорами – SAP, ORACLE, IBM, EMC, CISCO, HITACHI, FUJITSU и их партнерами.
И это только самое яркое, что отложилось в памяти. На самом деле мы получили грандиозный опыт и массу неоднозначных впечатлений. Несмотря на все перечисленные проблемы, сроки пилотного проекта сдвинулись всего на одну неделю – результат сплоченной командной работы. После таких пилотных проектов «продуктив» можно внедрять с закрытыми глазами, в этом их основная ценность.
Лучше один раз увидеть, чем сто раз услышать
Когда слышишь маркетинговые рассказы об эффектах тысячекратного ускорения обработки заданий от внедрения различных технологий, волей-неволей задумываешься о степени их правдоподобности. Так, на одной из конференций прозвучал доклад крупной металлургической компании, в котором говорилось, что в результате тестирования удалось ускорить отчет в 10 000 раз! Магия? Нет, это эффект, полученный при переходе со старого «железа» на современное оборудование последнего поколения в совокупности с переписыванием «кривого» кода. Когда слышишь о тысячекратных ускорениях, хочется спросить: «А что вы делали до этого?»
В нашем эксперименте тесты показали реальные результаты, и с некоторой погрешностью их можно интерпретировать как приближенные к продуктивному использованию. Общий эффект, наблюдаемый в результате пилотного проекта, в зависимости от технологии достигал четырехкратного увеличения производительности в дополнение к уменьшению хранимых данных, за счет сжатия и технологических особенностей. В одних случаях по отдельным отчетам действительно получилось ускорение работы пользовательских заданий в 10–20 раз, но в других (что обычно не упоминается в маркетинговых статьях), наоборот, происходило снижение скорости расчетов в несколько раз.
Прежде чем сделать выводы, нам потребовался год кропотливой работы, в том числе глубокий анализ, проведение нескольких масштабных «пилотов». На мой взгляд, все это является важной частью любого масштабного проекта по одной простой причине: потратить доллар можно только один раз, выбор решения такого класса осуществляется минимум на пять лет, и слишком велика цена ошибки. Здесь, как никогда, работает принцип «семь раз отмерь, а один отрежь».
Опубликовано 27.03.2014