







Применение подходов Chaos-Engineering в команде тестирования

Самые крупные сбои, например на ключевых дата-центрах, можно пережить с минимальными потерями, если начать с разработки особой микросервисной архитектуры и создания специализированных инструментов для тестирования — chaos testing. В этом также может помочь переход на облачную инфраструктуру. Все эти решения, безусловно, эффективны, но стоят немало и требуют значительных временных затрат и большой высококвалифицированной команды.
Российские ИТ-компании среднего и малого масштаба крайне редко могут в полную мощь использовать опыт зарубежных гигантов. Однако взять на вооружение некоторые практики будет нелишним. Самое важное — понимать принцип и главную цель хаос-инжиниринга: своевременно и регулярно обнаруживать проблемы, которые не устраняются должным образом, и обезопасить пользователей от влияния сбоев в ИТ-системах.
В малых и средних командах внедрением и использованием best practice хаос-инжиниринга может заняться QA-команда, которая будет организовывать и поддерживать процессы тестирования инфраструктуры, разрабатывать сценарии отказа системы, анализировать и фиксировать возникшие проблемы, выставлять приоритеты и продумывать поведение системы.
Применение хаос-инжиниринга при тестировании медицинского ПО
Рассмотрим на реальном примере, как QA-команда может организовать хаос-инжиниринг при тестировании микросервисного приложения.
Это веб-проект для врачей крупной клиники, где одной из ключевых фич приложения является аудиозапись с применением специализированного устройства с микрофоном в браузере через специальный плагин. Критичной ситуацией для данной фичи будет потеря данных при записи, поскольку доктор диктует диагноз пациента, анамнез или схему лечения. Такие случаи, когда врач надиктовывает информацию, а затем обнаруживает, что запись не ведется или потеряна, должны быть полностью исключены.
Для наглядности рассмотрим архитектурную схему фичи (схема представлена не в полном виде из-за NDA. — Прим. ред.).
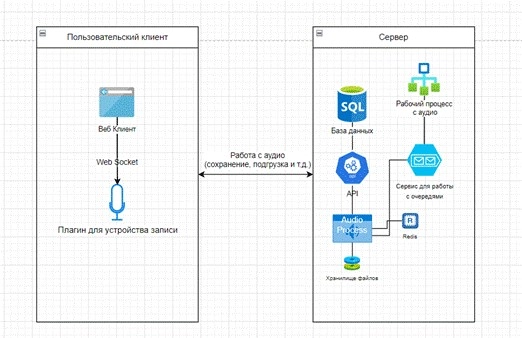
Для эффективного проведения стресс-тестирования необходимо определить точки отказа. Этот термин применяется к программным компонентам, при отказе которых система принимает нерабочее состояние. В нашем случае точками отказа являются компоненты, поломка которых может привести к потере записи аудио:
- База данных
- Сервер
- Веб-клиент
- Аудио-плагин
- Протокол связи
- Пользовательский ПК
В соответствии с принципами хаос-инжиниринга важно сформировать ряд гипотез, отображающих поведение системы при самых разных сбоях. Ниже приведем несколько возможных проблем, а также предположения, как должна вести себя система.
|
Точка отказа |
Возможная проблема |
Поведение системы |
|
Протокол связи |
Что будет, если у пользователя пропадет интернет-соединение. |
Аудио должно сохраниться на сервер, при сбое потеря аудио не должна превышать 1 секунду. Система уведомит пользователя о потере соединения. Система не позволит пользователю продолжить запись. Система будет выполнять попытки восстановить соединение |
|
Сервер |
Что будет, если при сохранении аудиофайла сервер будет недоступен. |
Аудио должно сохраниться на сервер, при сбое потеря аудио не должна превышать 1 секунду. Система уведомит пользователя о потере соединения с сервером. Система не позволит пользователю продолжить запись. Система будет выполнять попытки соединиться с сервером. |
|
Веб-клиент |
Что будет, если во время записи произойдет падение браузера. |
Аудио должно сохраниться на сервер, при сбое потеря аудио не должна превышать 1 секунду. Система позволит пользователю прослушать и завершить запись при входе в систему. |
|
Пользовательский ПК |
Что произойдет, если во время записи отключится электричество. |
Аудио должно сохраняться в процессе записи на сервер. Система позволит пользователю прослушать и завершить запись |
|
Аудио-плагин |
Что будет, если во время записи произойдет падение плагина. |
Аудио должно сохраняться в процессе записи на сервер. Система уведомит пользователя о проблеме с записью аудио. В случае наличия новой версии плагина предложит обновить его. Система не позволит пользователю продолжить запись. |
И это лишь малая часть вероятных сценариев, которые могут произойти при записи аудио. При любой нештатной ситуации для пользователя важно:
- Сохранить полученные данные
- Получить уведомление о проблеме
- Исключить ситуацию, когда система позволяет продолжить запись, но при этом не сохраняет данные
- Реализовать алгоритм восстановления процесса записи
- Получить возможность продолжить работу с записью после восстановления системы
Таким образом, разрабатывая фичу, архитектор совместно с аналитиком сразу минимизируют количество точек отказа и прорабатывают поведение системы при нештатных ситуациях. Помимо продуманной архитектуры, не меньшее значение имеет и качественное логирование. Например, важно логировать прерывание записи любым способом помимо стандартной функции завершения записи. Это поможет анализировать разные случаи, выявленные в медицинском учреждении, и повышать надежность системы.
Все сценарии формируются при общении с реальными пользователями, support-командой, а также при анализе баз данных и логов. На каждый из случаев должны быть разработаны сценарии поведения системы.
Часто можно встретить мнение, что хаос-инжиниринг должен проводиться на рабочих серверах, однако для медицинской сферы это слишком рискованно. Поэтому QA-команда проекта изучила самые частые пользовательские сценарии, которые могли приводить к сбоям:
- Медленное интернет-соединение и частое прерывание пакетов передачи данных
- Строгая политика безопасности при использовании браузера, что могло негативно повлиять на работу плагина
- Временное отключение устройства записи во время диктовки
- Доктор может забыть остановить запись и отойти к пациенту. Таким образом, на сервер может передаваться аудио длинной более пяти часов.
Благодаря использованию хаос-инжиниринга QA-команде проекта удалось найти и усовершенствовать архитектуру процесса записи. Ранее аудио сохранялось на пользовательский компьютер, что, во-первых, увеличивало количество возможных точек отказа, а во-вторых, в процессе тестирования выяснилось, что пользователи могут терять до 5 секунд аудио — а это критический дефект. На данный момент при любых сбоях потеря аудио может составлять максимум 1 секунду. Также мы смогли убрать риск недоступности или перезаполнения пользовательского жесткого диска.
Как внедрять хаос-инжиниринг в стратегию тестирования
Многие команды тестирования неосознанно проводят ряд проверок, связанных с надежностью системы. Однако хаос-инжиниринг — практика, которую необходимо выполнять на постоянной основе.
При внедрении данного подхода мы рекомендуем следовать такому алгоритму:
-
Выделить самую критичную функциональность для пользователей и негативные последствия. Часто это потеря данных, недоступность системы на определенное время, неверная отработка операций и т. п.
-
Отрисовать архитектуру и работу каждой из функций, определив критичные точки сбоя. Например, база данных, сервер, интернет-соединение, браузер и т. д.
-
На основе точек сбоя проработать и описать сценарии. К этому процессу важно привлечь всю команду, включая архитекторов, аналитиков, разработчиков и пользователей, так как сценарии могут оказаться весьма неожиданными, что видно на примере с забытым включенным микрофоном. Важно помнить, что некоторые сценарии могут быть достаточно сложными для воспроизведения, поэтому DevOps-специалисты становятся незаменимыми помощниками при внедрении хаос-инжиниринга.
-
Разработать гипотезы поведения системы при сбоях. Тут важно понимать и знать SLA или требования заказчика, а также специфику работы пользователей. Например, есть системы, которые должны быть восстановлены в течение 20–30 минут после сбоя, а пользователи должны четко понимать, когда им ожидать восстановления работы.
-
Провести все необходимые испытания. Команда должна самостоятельно решить, где и как проводить испытания по хаос-инжинирингу. Главное — оценить силы и затрачиваемое время на данные тесты и быть готовыми к экстренному восстановлению системы.
-
Зафиксировать и проанализировать полученные результаты, проработать и реализовать техническое задание для повышения стабильности и стрессоустойчивости системы.
-
Запланировать повторные испытания, проработать автоматизацию тестов. Важно не забывать, что тесты, которые проводились один раз, не являются гарантией стабильности системы. Это должны быть периодические испытания, в идеале — автоматизированные.
***
Мы разобрали лишь малый пример, как хаос-инжиниринг может помочь команде тестирования предотвратить крайне неприятные последствия разного рода сбоев, и не рассматривали специализированные инструменты. Погружаясь в эту область, необходимо расширять испытания и проверять не только работу приложения, но и тактику действий техподдержки при крупных падениях, скорость восстановления резервной БД и сервисов, отработку оповещения пользователей о произошедшем сбое и много другое. Данная область безгранична, а начать можно с малых и контролируемых участков тестирования.
Опубликовано 29.11.2023
