







Как сделать Linux-сервер счастливым долгожителем

В статье:
Почему важно предотвратить выход сервера из строя
Что нужно учесть на этапе инсталляции Linux-сервера
Как не допустить потери данных
Как предвидеть «непредвиденную» поломку
Почему важно предотвратить выход сервера из строя
Ни для кого не секрет, что серверы имеют свойство ломаться. Причем, словно обладая сверхъестественным чутьем, делают это в самый неподходящий для организации момент, например в конце отчетного периода, немало расстраивая руководство и, что самое страшное, клиентов. А расстройство клиентов, как мы знаем, грозит вылиться в немалые финансовые потери.
Что же может противопоставить такому серверному произволу обычная организация? Что можно сделать, чтобы сервер жил долго и счастливо и не умер в один день со всеми своими данными? Как говорит известная военная мудрость: «Хочешь мира — готовься к войне». В этой статье мы рассмотрим способы подготовки «личного серверного состава» компании, которые позволят ей предвидеть и своевременно приготовиться к возможному выходу сервера из строя, сократить время простоя и уменьшить вероятность потери важных данных.
Что нужно учесть на этапе инсталляции Linux-сервера
Как говорит другая военная мудрость: «Тяжело в учении — легко в бою». Потратив дополнительные средства и усилия на этапе комплектования и установки сервера, можно добиться значительного повышения его жизнеспособности.
Начать стоит с покупки источника бесперебойного питания. Качественное питание всех систем сервера — это, как и у людей, основа долголетия. Настоятельно рекомендуем приобрести «бесперебойник»: он имеет возможность сообщить серверу о том, что заряд батареи подходит к концу, и тот сможет штатным способом выключить сам себя и сберечь данные, да и оборудование от внезапного выключения. «Общаться» с ИБП Linux-серверу помогут специальные пакеты — apsupsd (для работы с ИБП APC) и NUT (для работы с множеством других ИБП). Перед покупкой «бесперебойника» рекомендуется ознакомиться со списком поддерживаемого оборудования на сайтах данных программ.

Повысить устойчивость дисковой системы к сбоям поможет RAID-массив — он состоит из нескольких дисков, которые представляются операционной системе как единая сущность. Суть данной конструкции в том, чтобы, используя избыточность дисков, повысить быстродействие и/или отказоустойчивость системы хранения данных в целом. В зависимости от распределения данных по дискам RAID-массивы делятся на соответствующие уровни. Быстродействие нас пока не интересует, поэтому будем рассматривать только уровни, которые повышают надежность системы и при этом не являются экзотикой, а именно: RAID1, RAID5 и RAID6, а также комбинированный RAID1+0 (он же RAID10). Существуют и другие комбинированные уровни RAID, а также разнообразные нестандартные способы построения подобных массивов. Например, пользователям операционных систем OpenSolaris и FreeBSD, кроме рассмотренных вариантов, можно порекомендовать RAID-Z (реализация RAID5 на базе технологий файловой системы zfs).

RAID-массивы могут формироваться как при помощи специальных плат расширения — RAID-контроллеров (аппаратный RAID), так и программными средствами (программный RAID). Каждый из способов имеет свои достоинства и недостатки. Программный RAID реализуется за счет ресурсов шины и процессора компьютера, к которому он подключен, не требуя при этом дополнительных финансовых вложений. Недостаток программного RAID в том, что загрузка операционной системы возможна только с RAID1 (ограничение BIOS). Хороший RAID-контроллер, в свою очередь, требует средств, но не будет нагружать вычислениями компьютер, к которому он подключен. Минус аппаратного RAID — формат хранения метаданных о разметке массива зависит от производителя. Это значит, что вы не сможете переставить диски из контроллера одного производителя в контроллер другого и продолжить работу с массивом. И это также значит, что при выходе из строя платы RAID-контроллера вам придется искать совместимую модель того же производителя, а в худшем случае — именно такую же модель, что не всегда реально.
В настоящее время многие модели RAID-контроллеров начального уровня (а также все контроллеры, интегрированные в материнские платы) являются полуаппаратными, то есть фактически реализуют только разметку диска, тогда как вся работа по организации массива перекладывается на плечи операционной системы. Такой режим работы практически не имеет смысла, поскольку для обслуживания потребует специального ПО (либо выполнения операций из «прошивки» контроллера во время загрузки компьютера), не дав при этом никакой реальной выгоды по использованию ресурсов компьютера. Плюс только в том, что в некоторых случаях такой контроллер позволяет запустить загрузку операционной системы с RAID, отличного от RAID1.
Таким образом, если вы планируете использование RAID1, что вполне подходит большинству небольших организаций, можно обойтись средствами операционной системы. Если же выбор пал на RAID5 или RAID6, то имеет смысл переложить работу с ними на отдельный контроллер. При этом лучше не экономить и взять контроллер с «батарейкой»: при отключении питания она позволит некоторое время хранить данные, которые не были записаны на диски, в памяти контроллера. RAID10 по ресурсоемкости можно организовывать программно, но загрузиться с программного RAID10 в общем случае не выйдет.
Итак, основной бонус RAID в том, что он позволяет избежать остановки бизнес-процессов при выходе из строя одного из дисков сервера (а в случае с RAID6/RAID10 — возможно, более чем одного). Кроме того, использование RAID позволяет вернуть сервер заменой диска в полную боеготовность силами неквалифицированного персонала, что важно в условиях среднего и малого бизнеса.
После установки и настройки сервера рекомендуется сохранить в файлах на отдельных носителях (а лучше еще и распечатать) следующую информацию:
· разметку всех дисков (например, вывод команд sfdisk -Gdx или fdisk -l);
· таблицу файловых систем (файл /etc/fstab);
· сообщения ядра, выводимые при загрузке (dmesg);
· результаты вывода программы lshw (или dmidecode, lspci).
Эта информация может значительно повысить ваши шансы на восстановление данных с жестких дисков сервера. Одну из копий рекомендуется сохранить в территориально удаленном месте.
Кроме того, рекомендуется подобрать LiveCD с Linux, удовлетворяющий следующим требованиям:
· поддержка используемого в организации оборудования;
· возможность установки используемого загрузчика;
· наличие утилит разметки диска (sfdisk/fdisk/cfdisk);
· наличие утилит для работы с нужными файловыми системами;
· поддержка выбранной системы резервного копирования.
Вывод: потратив средства на ИБП, дополнительные диски и, возможно, RAID-контроллер, а также время на создание RAID перед инсталляцией на сервер операционной системы и копий системной информации после, можно значительно снизить длительность потенциального простоя организации при выходе из строя сервера по причине сбоев аппаратного обеспечения.
Как не допустить потери данных
Важно понимать: RAID является исключительно средством, позволяющим серверу пережить потерю жесткого диска и за счет этого не допустить простоя бизнес-процесса организации. Но он не может защитить данные на дисках от случайной или намеренной порчи. Для этого необходимо, что называется, прикрыть тылы – производить регулярное резервное копирование.
Для начала стоит определиться с тем, что будет копироваться. Можно создавать образы дисков сервера или его разделов, а можно копировать непосредственно файлы с атрибутами или без. При использовании RAID делать регулярные образы диска не имеет особого смысла – для системных разделов достаточно сделать архивы файловых систем и упомянутую ранее схему разметки дисков с таблицей файловых систем. Пользовательские файлы нужно копировать с сохранением прав доступа на них.
Применяются следующие стратегии резервного копирования: полное, дифференциальное и инкрементальное. В первом случае создается полная копия исходных данных, но, поскольку их может быть очень много, имеет смысл делать копию не всех файлов, а только изменившихся с прошлого раза (это экономит как место в хранилище резервных копий, так и время на их создание). При дифференциальном копировании сохраняется разница между последней полной копией и текущим состоянием файлов, то есть копируются только файлы, изменившиеся с момента последнего полного копирования (для восстановления нужна последняя полная копия и последняя дифференциальная копия). Инкрементальное копирование сохраняет только файлы, изменившиеся с момента предыдущего инкрементального копирования (для восстановления нужна последняя полная копия и все инкрементальные копии с момента полного копирования). Обычно, используются комбинированные стратегии. Например, полная копия делается раз в неделю, дифференциальная — раз в сутки, а инкрементальная — раз в несколько часов. В общем случае выбор стратегии отталкивается от частоты изменения файлов и их объема.
Резервные копии могут храниться на ленте, оптических или жестких дисках. Проще всего делать копии на жесткие диски территориально удаленного сервера либо на внешние жесткие диски, которые будут уноситься из здания, где расположена организация. Делать копию на оптические диски (DVD/Blu-ray) имеет смысл, только если все данные умещаются на один такой диск. В противном случае это будет неудобно, а следовательно, этим перестанут пользоваться. Лучше делать копию автоматически на жесткий диск и потом (например, раз в неделю) вручную записывать на оптические диски для длительного хранения в другом помещении.
Для резервного копирования данных с большого количества машин можно воспользоваться специализированными системами, например Bacula или Amanda. Это клиент-серверные решения с богатыми возможностями по резервному копированию данных с различных операционных систем на различные носители. Возможно составить необходимую стратегию и расписание резервного копирования.
Для копирования данных с одного-двух серверов можно воспользоваться более простыми средствами, например star, rsync или rdiff-backup. Это достаточно разные программы, выполняющие различные задачи, но позволяющие достичь нужной цели — получить копию необходимых данных в нужном месте. Их недостаток в том, что всю логику и «обвязку» (расписание, стратегии) придется писать самостоятельно.
Самый простой и надежный способ резервного копирования для небольшой организации — использование rsync или rdiff-backup и двух внешних или съемных жестких дисков достаточного объема. Копирование можно проводить ночью, а днем ответственное лицо снимает диск, чтобы унести его домой (или в другое помещение), а на его место ставит принесенный. Кроме того, можно сохранять измененные файлы непосредственно на сервере, что ускорит восстановление случайно или намеренно испорченных или удаленных файлов.
Другой вариант — копировать данные на специализированный хостинг. Например, некоторые организации используют Amazon EC2 в качестве резервного хранилища. Кроме того, можно обратиться в компании, предоставляющие услуги резервного копирования в виде сервиса.
Как предвидеть «непредвиденную» поломку
К счастью, в большинстве случаев не нужно быть экстрасенсом, чтобы предугадать выход сервера из строя. Производители оборудования и программного обеспечения позаботились об этом.
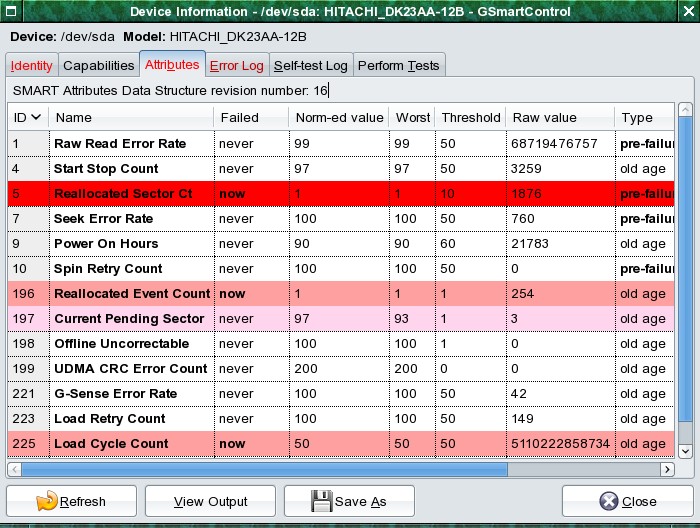
За состоянием жестких дисков можно следить посредством технологии SMART: она позволяет отслеживать состояние диска и периодически производить сканирование его поверхности. Для получения данных SMART с дисков применяется специальное программное обеспечение. Наиболее известный пакет для Linux — Smartmontools — включает в себя утилиту управления smartctl и демон мониторинга smartd. При помощи этого пакета можно отслеживать изменение данных SMART и запускать встроенные тесты жестких дисков по расписанию. Результаты мониторинга будут записываться в системный журнал через syslog. Отслеживание изменения данных SMART позволит предсказать скорый выход жесткого диска из строя по причине износа. Рекомендуется обращать внимание на следующие атрибуты SMART (в скобках приведен десятичный код атрибута): Reallocated Sectors Count (05), Seek Error Rate (07), Spin-Up Retry Count (10), Hardware ECC Recovered (195), Reallocation Event Count (196), Current Pending Sector Count (197), Uncorrectable Sector Count (198). Также стоит следить за температурой жестких дисков: HDA temperature (194) или Temperature (231).
Другие важные параметры, влияющие на продолжительность жизни сервера, предоставляются датчиками материнской платы: это может быть напряжение питания и температура отдельных компонент платы, а также скорости вращения вентиляторов, подключенных к ней. Для отслеживания состояния этих датчиков можно использовать пакет lm_sensors, в который входят утилита командной строки sensors и демон мониторинга sesnord. Информация об изменениях состояния датчиков также может быть направлена в syslog. Наблюдая за изменением предоставляемых параметров можно предвидеть проблемы с блоком питания сервера, материнской платой и системой охлаждения, что позволит своевременно среагировать и принять адекватные меры.
Немало неприятностей способно доставить и неожиданно закончившееся место на дисках сервера, как на системных разделах, так и на разделах с пользовательскими данными. На системных разделах это может привести, например, к невозможности записи вышеописанных изменений в системные журналы. Нехватка места на разделах с пользовательскими данными чревата невозможностью сохранить изменения в важном документе, а при неудачном стечении обстоятельств — и к потере последнего. Отслеживать свободное место на дисках можно при помощи самописного инструмента, использующего утилиту df, или же через протокол SNMP при помощи пакета Net-SNMP. Использование SNMP позволяет наблюдать и за массой других параметров: загрузкой процессора, сетевых интерфейсов, распределением памяти и т. д.
Свести все эти показания воедино поможет система мониторинга: входящие в нее специализированные программные пакеты позволяют собирать и хранить данные с различных подсистем. Для наших целей также необходима возможность рассылки предупреждений при выходе их за определенные рамки. Приятным дополнением станет возможность увидеть динамику изменения наблюдаемых параметров на графиках. Примерами таких систем являются Zabbix и Nagios. К сожалению, подобные системы рассчитаны на мониторинг сетей из сотен устройств, поэтому их использование для отслеживания показателей одного-двух компьютеров может показаться стрельбой из пушки по воробьям.
Что дальше?
Приведенные нами способы позволяют добиться достаточного уровня жизнеспособности сервера. Если же бизнес-процесс компании крайне критичен к простою и задержкам, то имеет смысл рассмотреть установку резервного сервера аналогичной конфигурации. Для построения отказоустойчивой конфигурации можно использовать пакеты DRBD и Heartbeat.
Следующим шагом будет обеспечение постоянного доступа в Интернет или доступности сервера из сети Интернет. Но это уже совсем другая история.
Опубликовано 09.03.2011