







Какой сценарий выбрать: «теплый», «холодный» или «горячий» резерв?

Теневое копирование? Дедупликация? Быстрые, дорогие «горячие» – и медленные, но дешевые хранилища (стоимость за гигабайт) и т. п.? Но ведь резервирование и отказоустойчивость – это же разные технологии. Облака – да, могут обеспечить и то и другое, но зачем это мешать в одну кучу? Между тем те же специалисты охотно и активно используют новые технологии ИТ-трансформации и дешевеющие облачные сервисы, не задумываясь, что фактически с помощью облака решают сразу несколько задач, в том числе отказоустойчивости и резервирования.
Немного печальной статистики, большая ложка дегтя в бочке меда традиционного резервного копирования. В 2020 году независимая исследовательская компания провела опрос, в котором приняли участие 3000 ИТ-специалистов из 28 стран. Выяснилось, что только 63% заданий резервного копирования выполняются в срок и без ошибок, а 33% заданий восстановления данных завершаются с ошибками или не завершаются вообще.
И при этом перед любой компанией стоят задачи сохранности данных/информации, обеспечения отказоустойчивости с необходимым минимальным временем простоя и защиты от угроз, в частности различных видов вирусной активности, в том числе так называемых вымогателей-шифровальщиков. Например, по данным исследования компании Forester, основные причины сбоев и простоя бизнеса следующие:
.png)
С учетом новых вызовов нашего времени:– взрывного роста количества сотрудников на удаленном режиме работы при постоянно возрастающем количестве и сложности атак на системы безопасности – ИТ-службы находятся в постоянно сжимающихся тисках ограниченности ресурсов (времени, бюджета, кадровых), а также требований к непрерывности бизнес-процессов. Поэтому непрерывность работы компании и защита данных стали главными приоритетами. Проблемы растут, медлить нельзя.
В недавно проведенном опросе 1500 ИТ-специалистов по всему миру было озвучено пять основных причин, которые заставляют задуматься о модернизации традиционных методов и решений резервного копирования:
-
«Мое текущее решение для резервного копирования ненадежно».
-
«Если просуммировать все, что вы платите, в итоговой строке может получиться слишком большая сумма».
-
«Заявленная окупаемость инвестиций (ROI) никогда не реализуется».
-
«Восстановление данных занимает много времени, а окно резервного копирования слишком большое».
-
«Это занимает слишком много моего времени и ресурсов».
Компания Veeam так обобщила эти доводы, вынуждающие потребителей используемые решения:
-
Ненадежность.
-
Слишком высокая стоимость.
-
Проблемы с окупаемостью инвестиций.
-
Медленное восстановление.
-
Нехватка времени и ресурсов.
При этом современным компаниям для успешного развития и обслуживания ИТ-инфраструктур и сервисов также важно уметь интегрировать ИT-ресурсы в офисе и облаке и эффективно распределять ИТ-сервисы по нескольким облачным платформам с сохранением их логической целостности.
Выбирая тот или иной инструмент или решение, мы сталкиваемся с необходимостью предусмотреть многочисленные сценарии, которые, с одной стороны, обеспечат требования безопасности и отказоустойчивости, а с другой позволят развивать ИТ-сервисы с необходимой скоростью. Как всегда, на чаше весов несколько противоречивых требований. И задача ИТ – провести тщательный анализ и найти необходимый баланс при выборе решений – осложняется тем, что технологии стремительно развиваются, обеспечивая с опережением необходимый уровень развития кампаний и цифровой трансформации. И, казалось бы, только вчера купленное совсем недешевое, но такое «железное» решение с дорогими сердцу и кошельку ленточными или многодисковыми устройствами уже утром не обеспечивает новые сценарии резервирования и модернизации. С одной стороны, экспоненциально растут обрабатываемые и резервируемые объемы информации, пухнут базы данных, разработчики требуют космической скорости развития сервисов, с другой – бизнес требует 100%-ной сохранности и нулевого времени простоя, но с возможностью быстрой миграции нагрузок и данных между платформами и провайдерами.
Согласно результатам опроса, 50% средних и крупных компаний не могут продолжать функционировать в случае, когда ИТ-системы недоступны более часа. Если важна непрерывносьбя работы ИТ-системы, а простой несет большие потери, крайне важно найти сбалансированное решение и план аварийного восстановления.
Отличия обычного резервного копирования и сценариев резервирования
|
В чем различия |
Backup |
Disaster recovery / «Резервный ЦОД» |
|
Требования к хранению |
Данные копируются с определенной частотой (ежедневно, еженедельно, ежемесячно) |
Репликация данных происходит непрерывно в режиме реального времени |
|
Возможность восстановления данных |
Восстановление только потерянной информации |
Процесс переключения основной инфраструктуры компании на альтернативную |
|
Потребности в дополнительных ресурсах |
Необходимо только место в хранилище данных |
Является полной или частичной копией ИТ-инфраструктуры компании, включая физические ресурсы, программное обеспечение и т. д. |
|
Планирование отказоустойчивости |
Не является инструментом обеспечения отказоустойчивости, так как не обеспечивает резервирование самой инфраструктуры |
Это главный параметр DR. Реконфигурация сети автоматизирована, и включает в себя, при необходимости, замену IP-адресов, позволяет оперативно получить доступ к приложению и данным на резервной площадке и продолжить работу. |
|
Результат |
Копия данных |
Работающая копия ИТ-системы на резервном сервисе |
Но у большинства опрошенных выбор с учетом требований, возможностей и бюджета решения вызывает сложности. На первом этапе надо сравнить традиционное резервное копирование со сценариями резервирования и определить, какое решение обеспечит требования бизнеса.
Отличия обычного резервного копирования и сценариев резервирования
|
Размер бизнеса |
< 1 минуты |
до 1 часа |
до 1 дня |
несколько дней |
|
Малый |
17% |
9% |
45% |
28% |
|
Средний |
30% |
20% |
21% |
29% |
|
Крупный |
28% |
22% |
31% |
19% |
Виды и параметры резервирования
Для оценки необходимого уровня резервирования и отказоустойчивости ИТ-сервисов используются три основных параметра, которые определяются требованиями и существенно влияют на стоимость любого решения:
-
RTO (Recovery time objective) – время, за которое возможно восстановить ИТ-систему.
-
RPO (Recovery point objective) – сколько данных будет потеряно при аварийном восстановлении.
-
RCO (Recovery capacity objective) – какую часть нагрузки должна обеспечивать резервная система (может измеряться в процентах, транзакциях ИТ-систем и других величинах).
Для поиска оптимального решения можно использовать простую логику: оценить и соотнести стоимость простоя и стоимость решения:
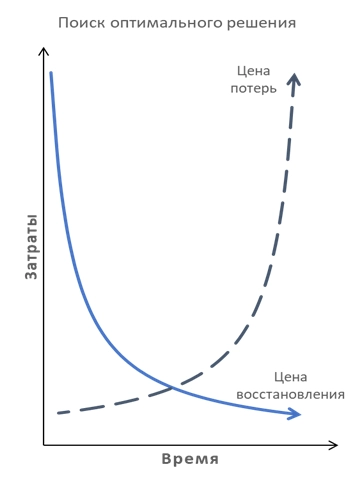
Для решения этих сложных и противоречивых задач воспользуемся проверенной методикой типизации и упрощения сценариев, разбив их на три основные группы, в каждой из которых предпочтителен тот или иной подход. В результате несложных обобщений получаем три варианта, которые самостоятельно или в комбинации решают свыше 90% задач резервирования:
-
«Холодный» резерв – для репликации и резервного копирования любых данных в удаленное облачное хранилище.
-
«Теплый» резерв – полнофункциональная резервная или вспомогательная площадка на случай прекращения работоспособности основной площадки или временного расширения нагрузки.
-
«Горячий» резерв – решение с максимальным уровнем отказоустойчивости информационных систем или отдельных решений.
«Холодный» резерв простейшем виде может быть обычным резервным копированием с необходимой глубиной хранения.
ПРИМЕР:
Офисная инфраструктура через site-to-site VPN подключается к облачной. Настраиваются правила резервного копирования (перечень ресурсов, периодичность, глубина и т. п.). В случае потери данных в офисе они будут гарантированно восстановлены из географически удаленного ЦОДа (в том числе в случае катастрофы).
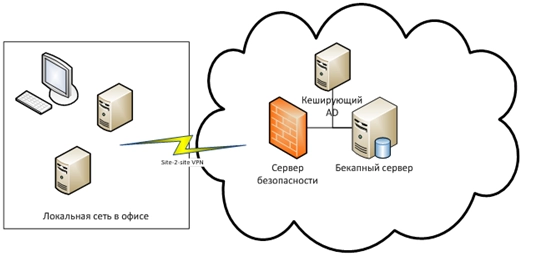
«Холодный» резерв
«Теплый» резерв может быть организован на основе быстрого резервного копирования с минимально возможным временем потери и восстановления информации и состояния системы. Это может быть «горячий» резерв только части сервисов, например базы данных или иных систем в режиме репликации без активного использования вычислительных мощностей (процессоров и памяти). Важно решить, какую часть нагрузки должна обеспечивать резервная система и, если необходимо, возможное время развертывания резервной площадки на полную или частичную мощность.
ПРИМЕР:
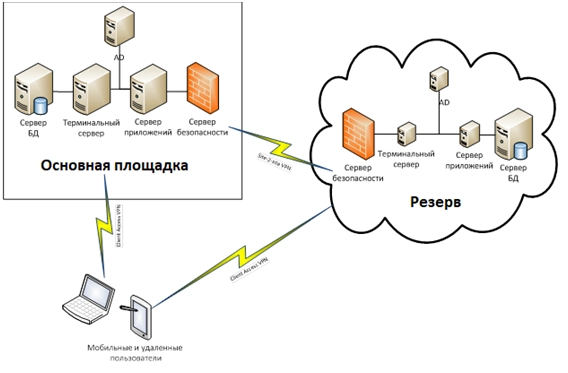
«Теплый» резерв
«Горячий» резерв может совмещать максимальную отказоустойчивость, геораспределенность и балансировку нагрузки как на уровне приложений, так и на платформенном уровне: уровне операционных систем и систем хранения.
ПРИМЕРЫ:
.png)
.png)
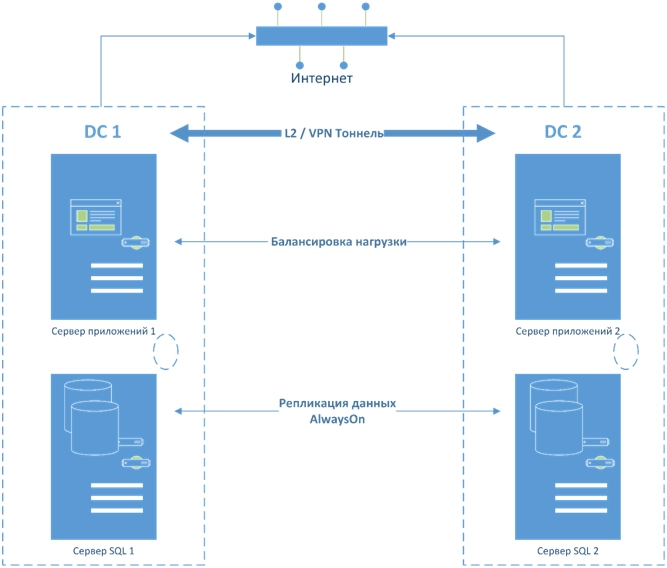
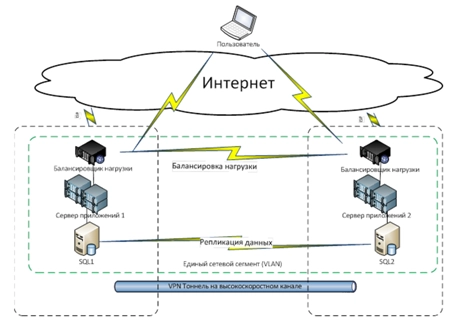
«Горячий» резерв/геокластер
Что выбрать?
Выбирая золотую середину, мы фактически удовлетворяем приоритеты: допустимое время простоя, риски, бюджет решения и, что сейчас все более важно, – необходимую гибкость решения. Это должно обеспечить развитие ИТ-сервисов за минимально возможное время и вероятную смену приоритетов, так как, например, самый сложный и дорогой сценарий «горячего» резервирования благодаря стремительному развитию облачных технологий сейчас становится невероятно доступнее.
Как подсказывает практика, в большинстве случаев решения с использованием «теплого» резервирования с обычным резервным копированием позволяют решить большинство задач обеспечения необходимого баланса между требованиями минимального времени простоя, необходимой глубины хранения и версионности, бюджета и запаса гибкости.
На рынке сегодня большое количество узкоспециализированных и достаточно универсальных решений. С целью экономии и упрощения можно выбрать, например, универсальные продукты от Veeam или решать эти задачи дискретно, с учетом специфики и/или требований обеспечения более глубокого уровня решения. При выборе важно избежать лишних затрат и сложностей, связанных с созданием и сопровождением собственной резервной площадки, но при этом обеспечить минимальную потерю данных и быстрое восстановление в случае сбоя основной площадки.
Итак, фокусируемся на следующих основных требованиях:
-
Быстрое развертывание. Решение не должно быть слишком сложным и/или подключение и настройка сервиса осуществляются в кратчайшие сроки специалистами провайдера.
-
Сокращение затрат на инфраструктуру. Решение должно позволять сократить расходы на развертывание, мониторинг и поддержку резервной площадки с оплатой только использования сервиса и используемых ресурсов по фактическому потреблению.
-
Минимально возможное время простоя и потери данных благодаря надежному восстановлению и частоте реплик.
Давайте сравним решения от Veeam и VMware на примере сервисов для задач «холодного» и «теплого» резервирования, а также миграции между площадками, платформами и даже провайдерами.
С помощью Veeam Cloud Connect можно настроить непрерывную репликацию в облако и быстро переключиться на реплику в случае аварии на основной площадке. Все операции выполняются в Veeam Backup and Replication. Этот сервис подходит лучше всего в следующих случаях:
-
Для построения полноценной резервной площадки с минимальными затратами.
-
Для оперативного восстановления работоспособности ИТ-сервисов в случае сбоя.
-
Необходимо реплицировать виртуальные машины на VMware и Hyper-V.
-
Необходимо делать дополнительные копии бэкапа в облаке, например, по схеме «3-2-1».
-
Если уже используется Veeam Backup and Replication.
Преимущества:
-
Поддержка работы с VMware, MS Hyper-V, Nutanix AHV и решения Veeam Agent для Linux.
-
Централизованное решение для управления резервным копированием и репликацией на объединяемых площадках.
-
Независимый портал управления может находиться в надежном облаке провайдера.
-
Возможность использовать сжатие трафика, особенно при использовании интернет-каналов со слабой пропускной способностью.
-
Возможность настраивать очередность запуска виртуальных машин в случае сбоя основной площадки.
-
Поддержка работы с VMware vCloud Director.
-
Минимальное время потери данных – от 1 минуты.
Сценарии использования:
-
Резервное копирование данных из офисной инфраструктуры в ЦОД/облако.
-
Аварийное восстановление из офисной инфраструктуры в облако.
-
Аварийное восстановление между ЦОДами/облаками.
VMware vCloud Availability позволяет осуществлять аварийное восстановление и миграцию виртуальных машин между различными площадками виртуализации инфраструктуры, например из офисной инфраструктуры в облако провайдера. С помощью vCloud Availability можно настраивать параметры репликации и восстановления для каждой виртуальной машины. В случае падения основной площадки виртуальные машины будут запущены в облаке.
Этот сервис предпочтителен в следующих случаях:
-
Построение полноценной резервной площадки с минимальными затратами.
-
Нужна возможность оперативного восстановления систем в случае сбоя.
-
При необходимости построения гибридного облака с возможностью автоматической миграции ВМ в облако.
-
Уже используется виртуализация Vmware.
Преимущества:
-
Интеграция с порталом vCloud Director.
-
Настройка заданий миграции и репликации.
-
Выбор политики хранения данных.
-
Возможность изменения сетевых настроек на резервной площадке.
-
Возможность тестирования.
-
Мониторинг выполнения заданий репликации.
-
Поддержка создания точек восстановления.
-
Минимальное время потери данных – от 5 минут.
Сценарии использования:
-
Миграция ресурсов из офисной инфраструктуры в облако и обратно в любой момент.
-
Построение гибридной облачной инфраструктуры за считаные минуты.
-
Аварийное восстановление из офисной инфраструктуры в облако.
-
Аварийное восстановление между двумя ЦОДами в облаке.
Сравнение Veeam Cloud Connect и VMware vCloud Availability
|
Функции |
Veeam Cloud Connect |
vCloud Availability |
|
Настройка RPO |
От 1 мин |
От 5 мин |
|
Единая сеть L2 |
Нет |
Да |
|
Безопасность |
SSL/TLS-канал |
SSL/TLS-канал |
|
Поддерживаемые платформы виртуализации |
VMware, Hyper-V |
VMware |
|
Простота установки |
Инфраструктура Veeam B&R |
Одна служебная ВМ на стороне заказчика |
|
Требуются дополнительные сервисы управления миграцией |
Да (сервер+агенты на каждую ВМ) |
Да |
|
Требуются дополнительные лицензии |
Да |
Нет |
|
Требуется совместимость версии vSphere |
Нет |
Да |
|
Требуется создание сервисов и инфраструктуры с нуля |
Нет |
Нет |
|
Варианты использования |
On-premise <-> Cloud DR |
On-premise <-> Cloud DR |
|
Репликация изменённых данных ВМ |
Да |
Да |
|
Холодная миграция |
Да |
Да |
|
Горячая миграция |
Да |
Да |
|
Миграция без доступа к системе виртуализации |
Да |
Нет |
|
Миграция железных серверов |
Да |
Нет |
|
Дополнительные траты на сервис для заказчика |
Да: лицензии Veeam. Работы опционально |
Нет |
Заключение и выводы
Если обобщить основные потребности, получаем следующую статистику требований к новым решениям резервирования:
-
Повышение надежности (количества успешных завершений) резервного копирования на 39%.
-
Снижение затрат на ПО или оборудование на 38%.
-
Повышение окупаемости инвестиций (ROI) / снижение совокупной стоимости владения (TCO) на 33%.
-
Улучшение показателей RPO/RTO на 30%.
-
Снижение сложности эксплуатации (например, простота использования) на 30%.
.png)
Новое решение для резервирования должно:
-
работать по принципу «настроил и забыл», вселяя уверенность, что данные в нужный момент будут восстановлены;
-
иметь простую и гибкую ценовую модель и быть совместимым со всем используемым оборудованием и хранилищами;
-
предусматривать бесплатный тестовый период;
-
иметь различные варианты восстановления для соответствия требованиям любых SLA;
-
быть инновационным и иметь подтвержденные примеры успешного использования заказчиками;
-
не должно занимать много времени на его изучение и внедрение, позволяя ИТ-специалистам сосредоточиться на других задачах и приоритетах.
Практически все эти требования отлично сочетаются в решении «Резервный DC/ЦОД», которое может быть построено на сервисах Veeam или vCloud Availability.
Резервный/вспомогательный ЦОД должен обеспечивать:
-
аварийное восстановление и репликацию данных;
-
защиту от рисков и связанных с ними убытков;
-
возможность оперативно восстановить данные;
-
размещение в отказоустойчивых ЦОДах Tier III;
-
тарификацию только за реально использованные ресурсы.
В зависимости от требований и бюджета может быть организована репликация всей ИТ-инфраструктуры («горячий» резерв) или ограниченная/минимальная по виртуальным мощностям инфраструктура, например в режиме вспомогательного и резервного DC/ЦОДа («теплый» или «холодный» резерв).
В облаке размещается резервная или вспомогательная ИТ-инфраструктура, а основная – на площадке заказчика или в другом облаке.
Решение «Резервный/вспомогательный ЦОД» проще, безопасней и выгодней размещать в облаке надежного провайдера, где оно успешно используется в следующих вариантах работы:
-
«Холодный», «теплый» и «горячий» резерв, резервный ЦОД с запуском по требованию. В случае отказа основной площадки приложения и сервисы автоматически запускаются на другой (обеспечение непрерывности бизнеса).
-
Решение вспомогательных задач: тестовые площадки под новые проекты, среды для разработки, кросс-миграция между ИТ-площадками для целей модернизации и оптимизации ПО и аппаратного обеспечения, масштабирование вычислительных ресурсов при пиковой нагрузке, эластичные ИТ, быстрое развертывание дополнительных сервисов и рабочих мест.
- Резервный ЦОД с гибридной и комбинированной инфраструктурой – оптимальное решение для крупных ИТ-инфраструктур, часто используемое в комбинации с услугами Dedicated и Colocation.
Опубликовано 15.09.2021